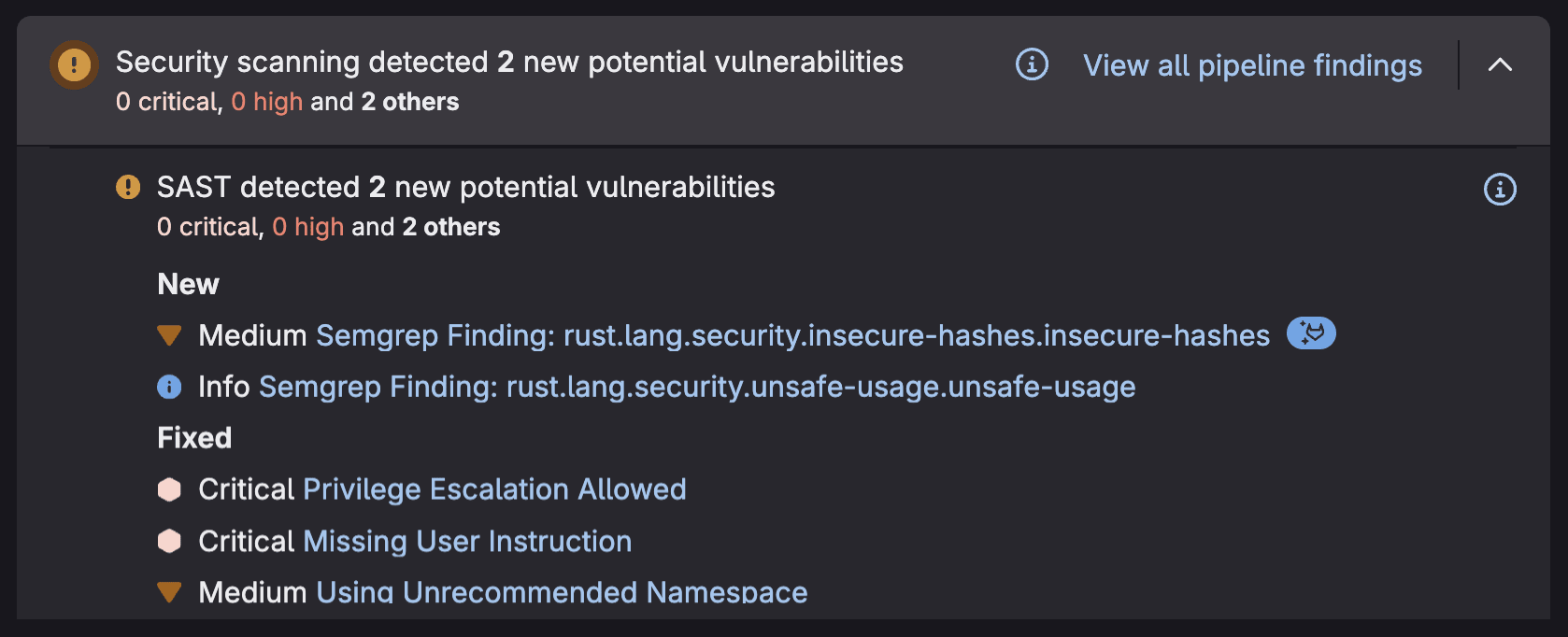
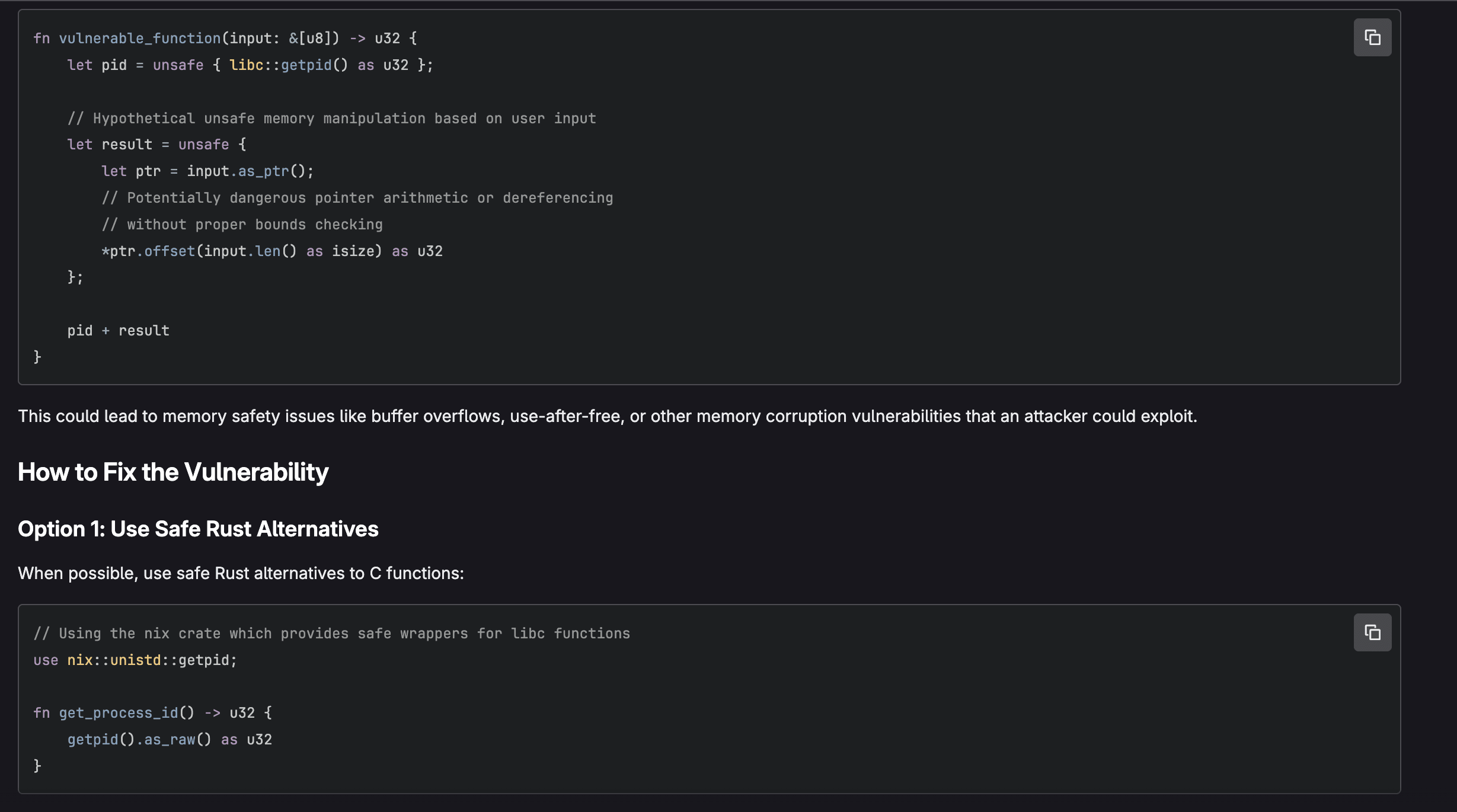
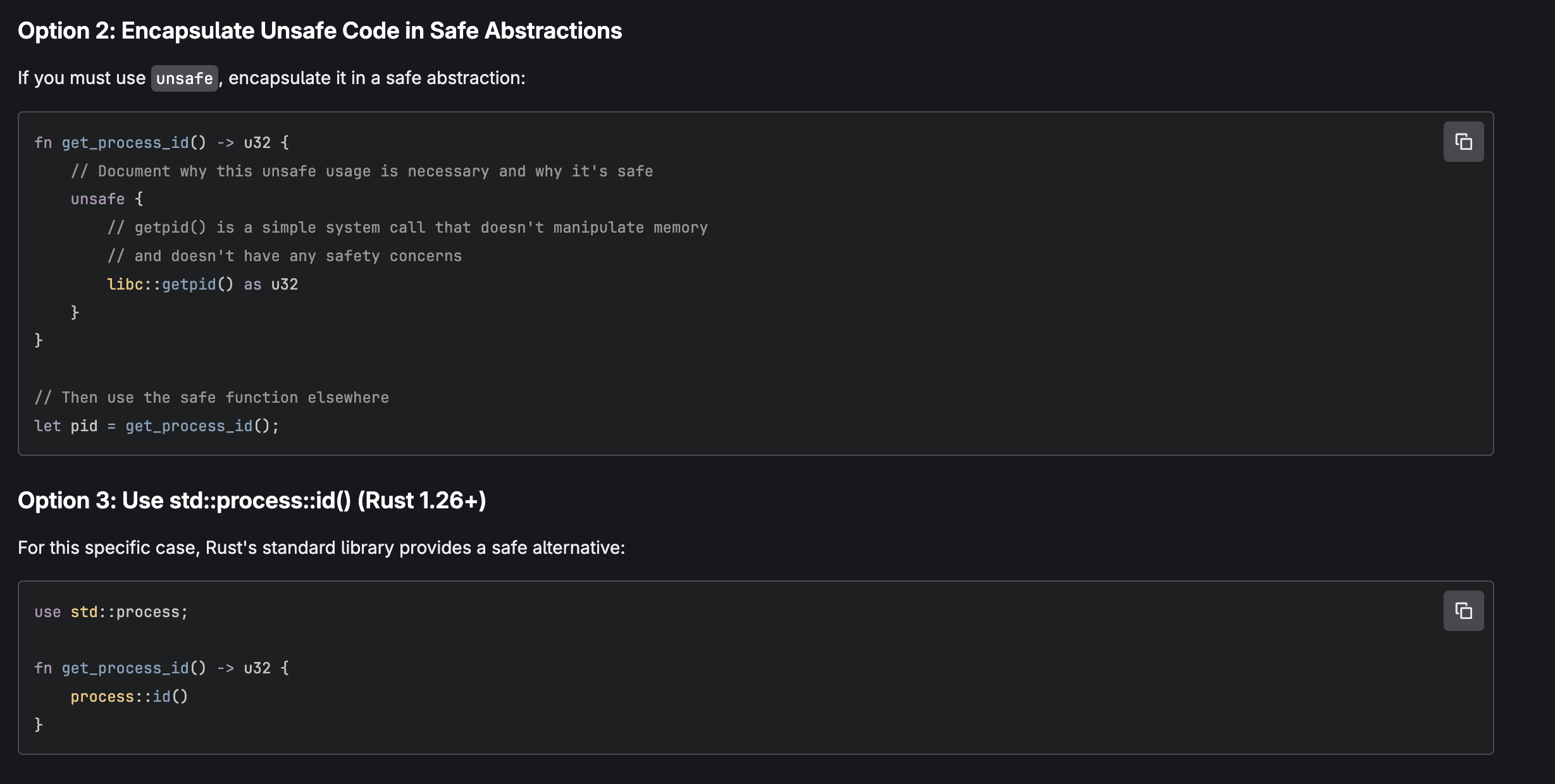
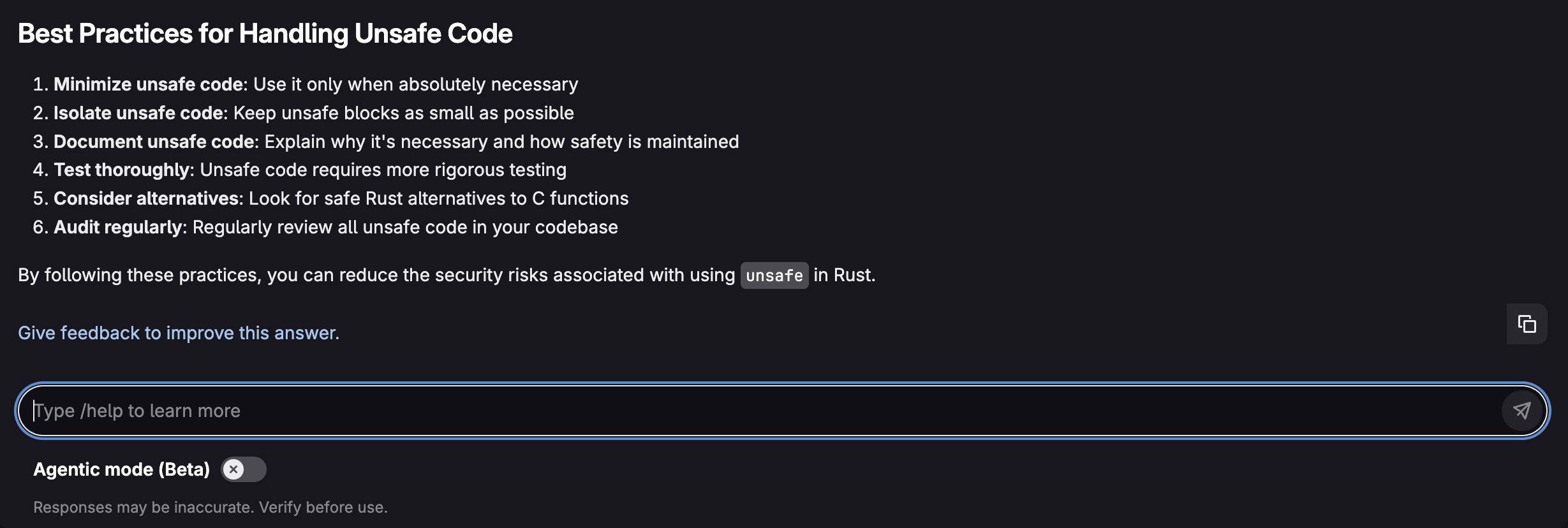
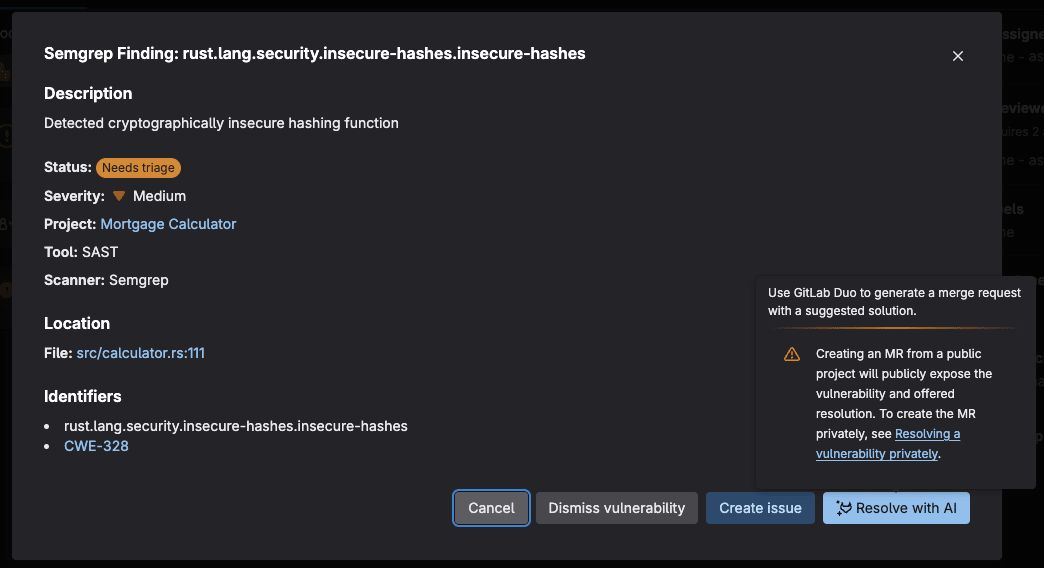
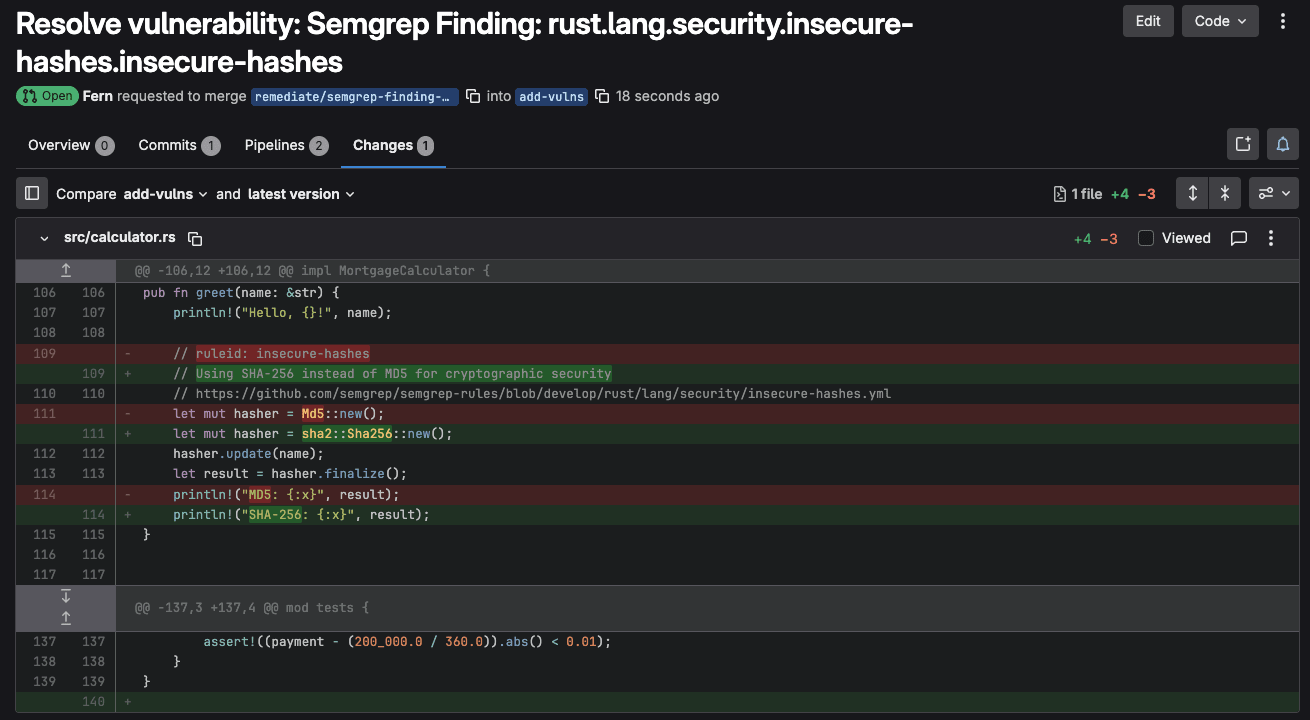
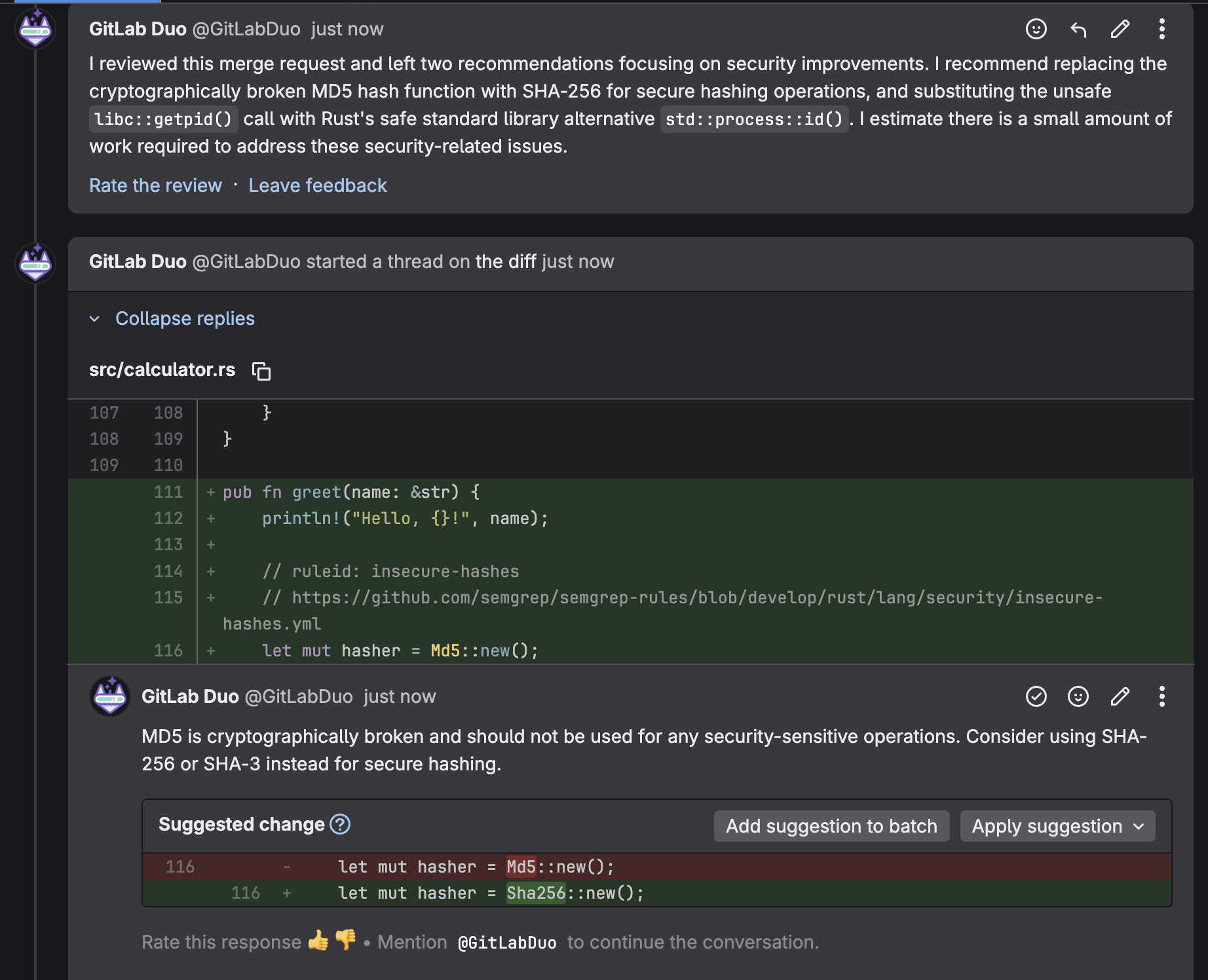
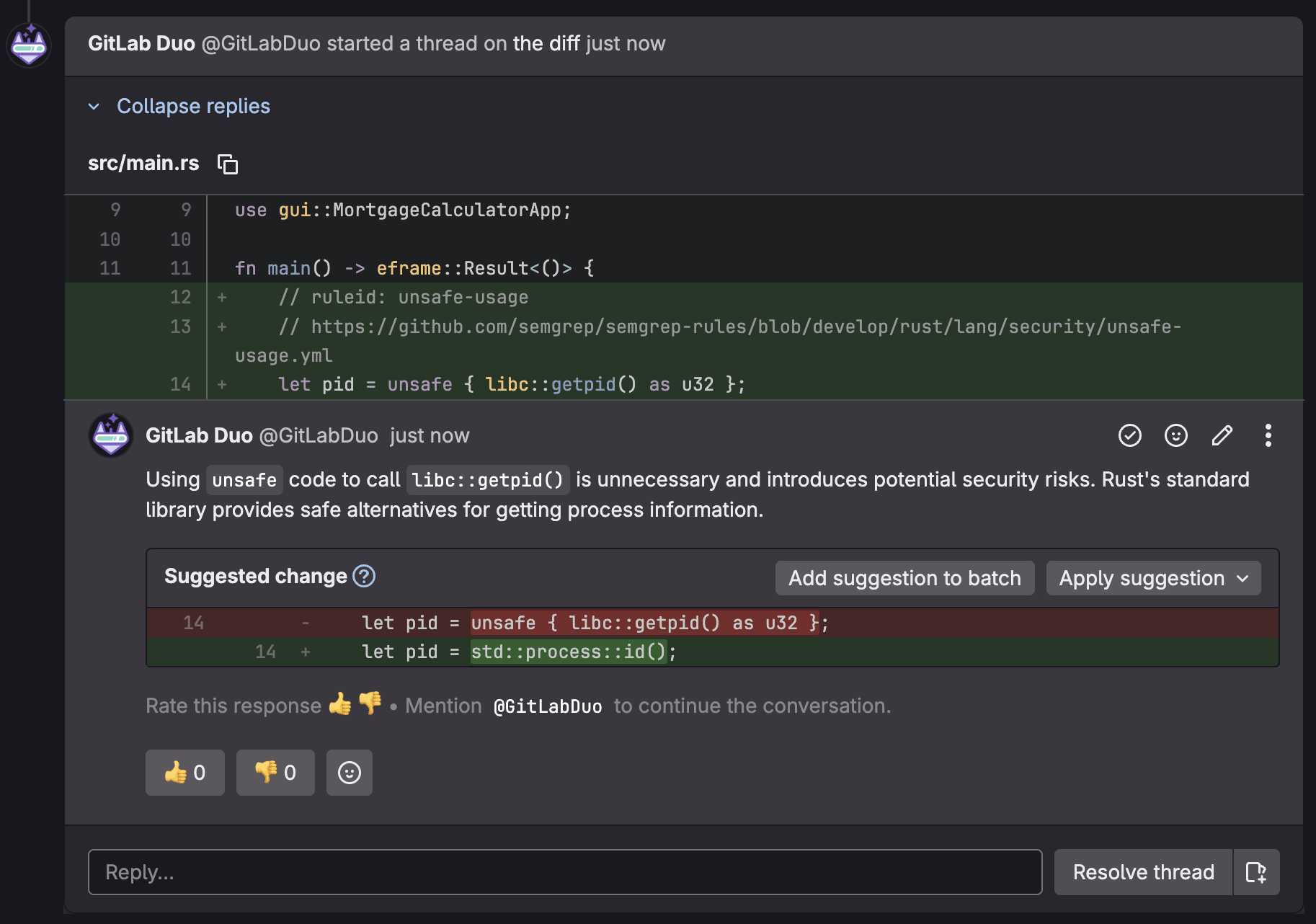
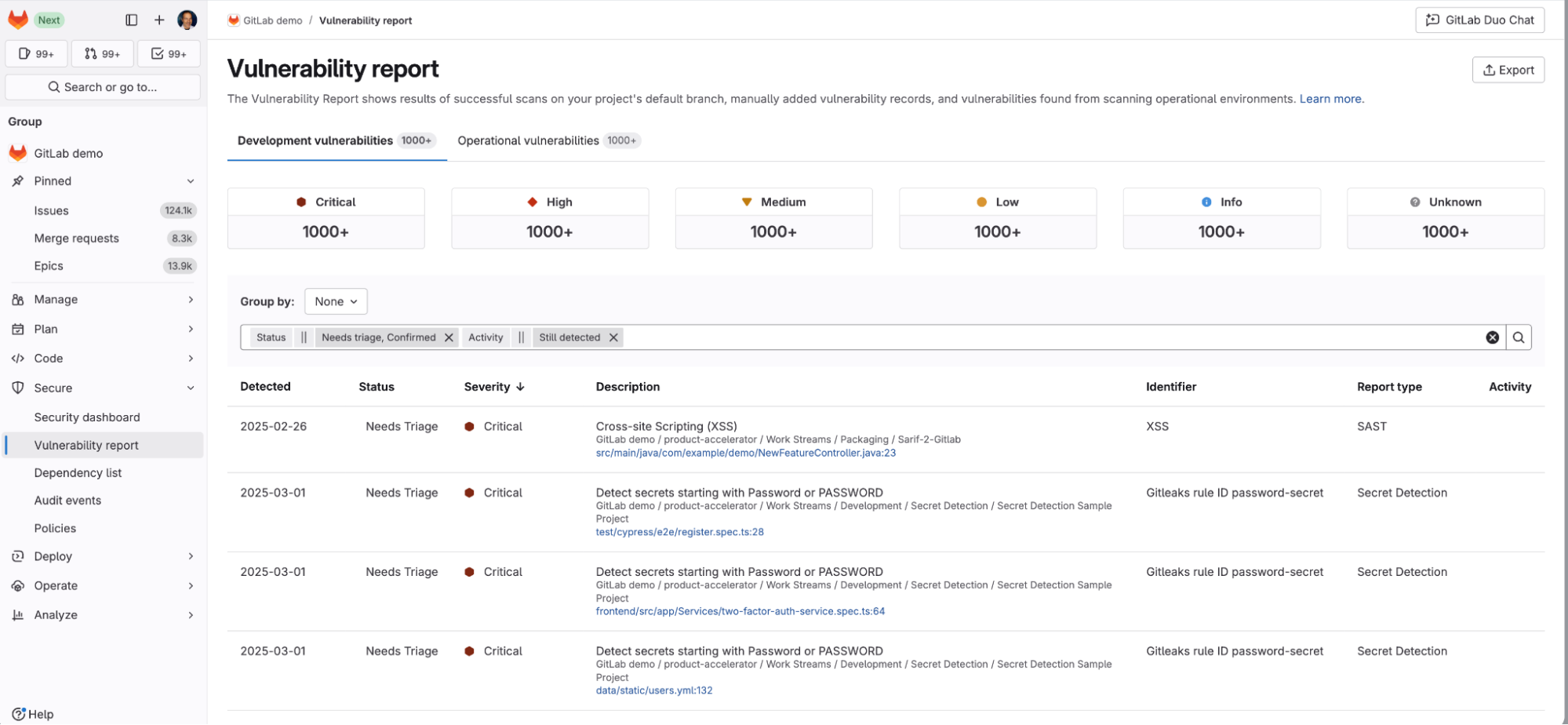
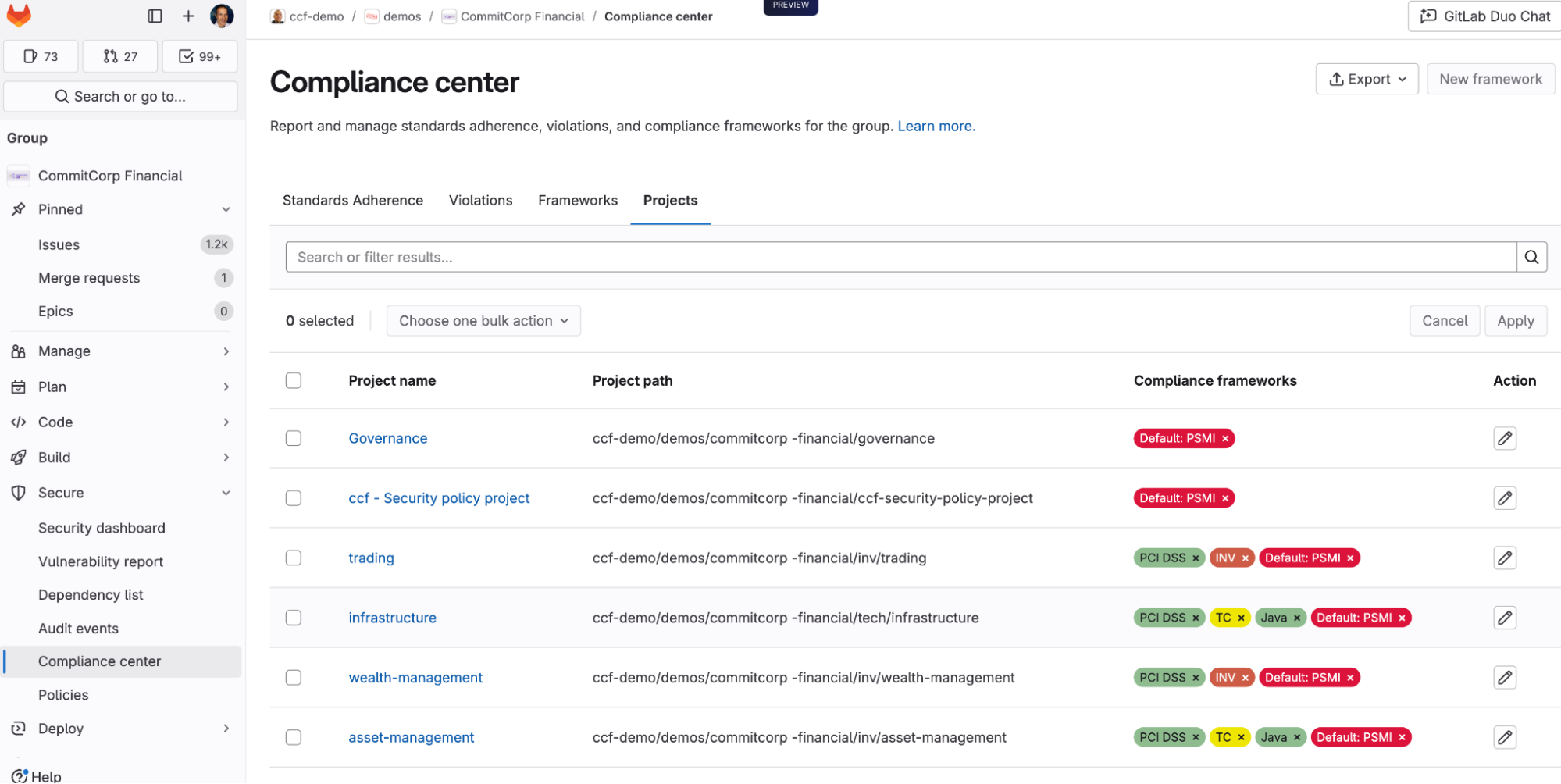
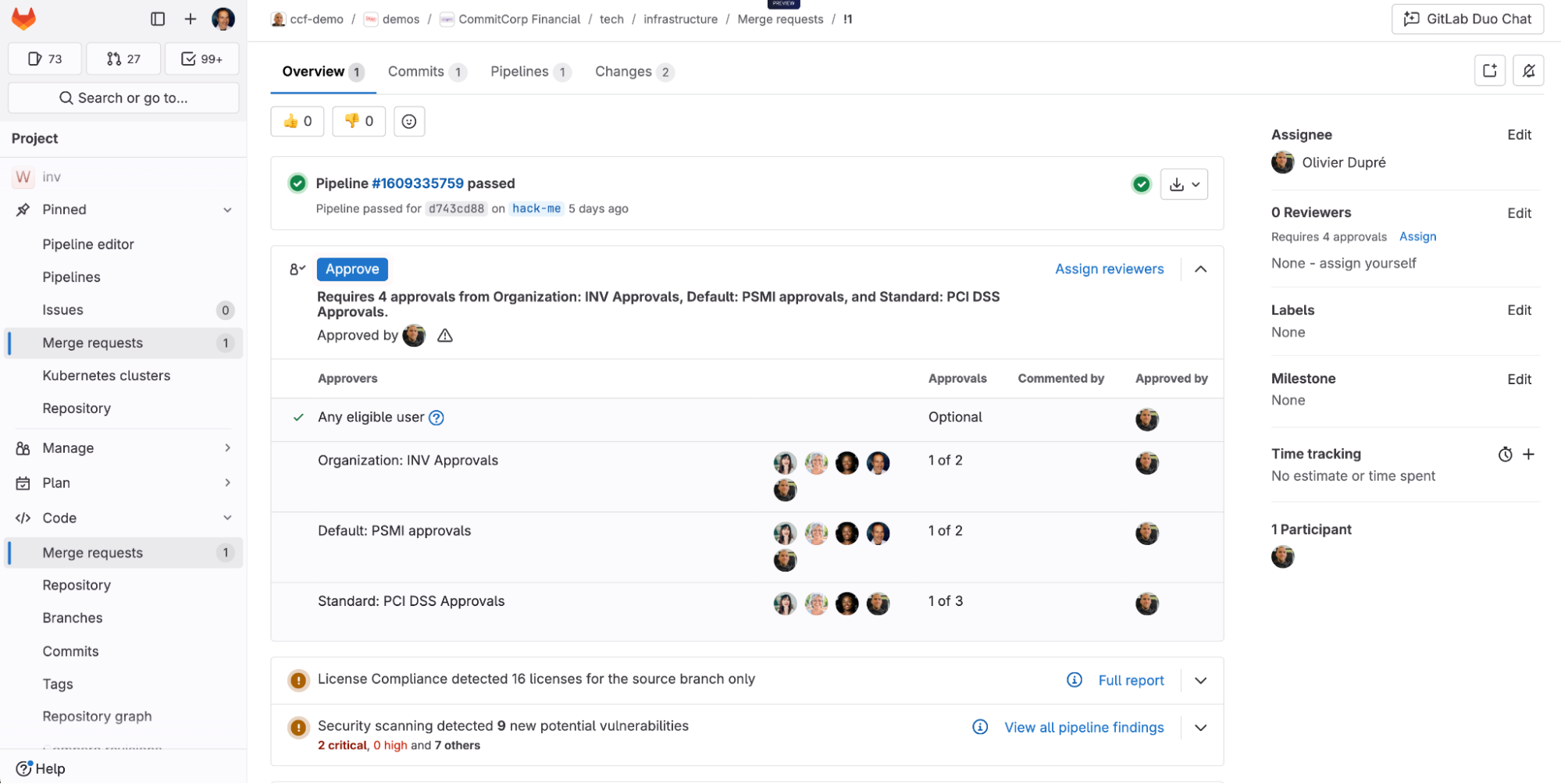
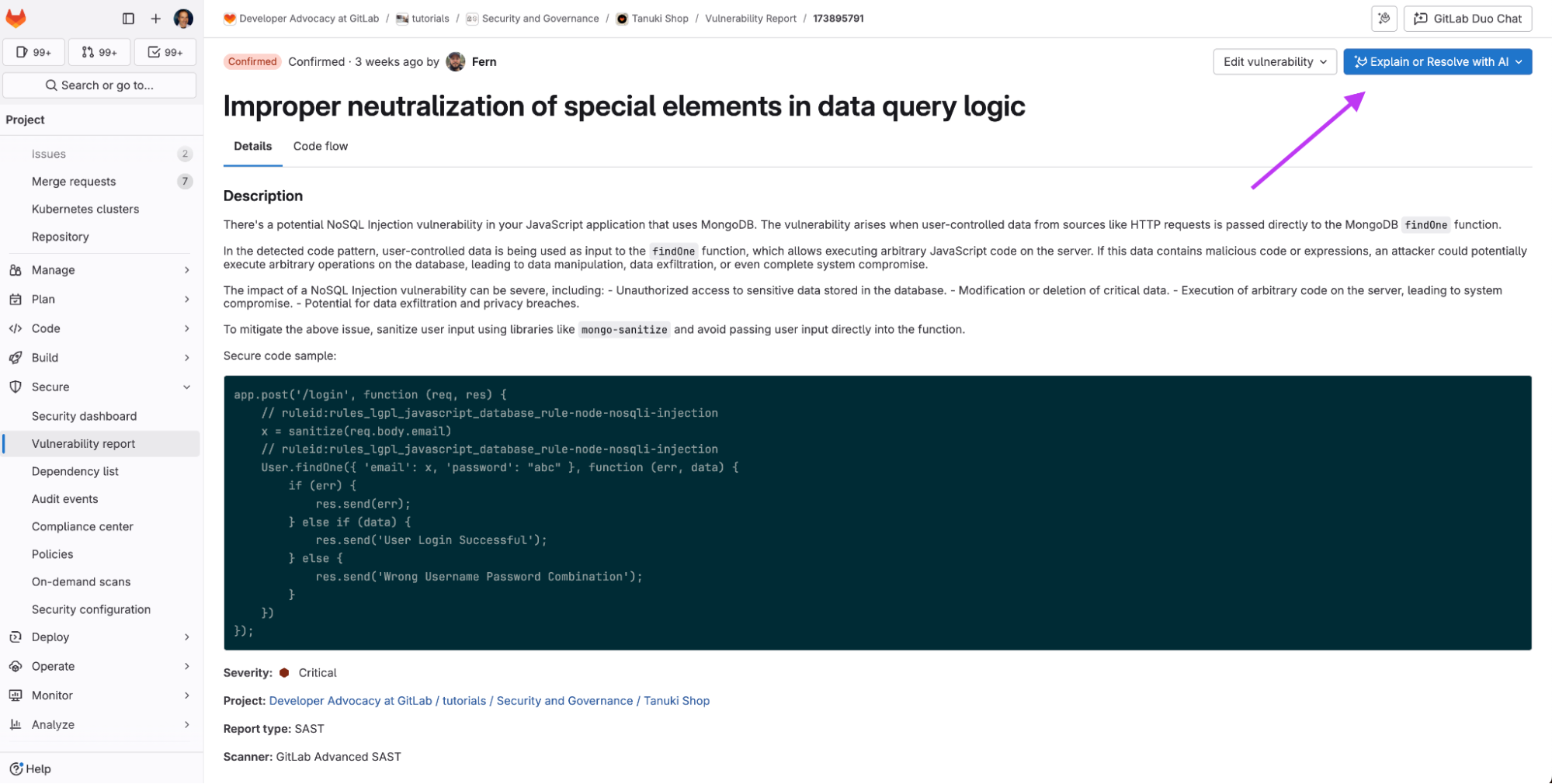
Mettre en production un modèle n’est pas qu’une question d’entraînement. Entre la préparation des données, le déploiement, le suivi des performances et la maintenance, les équipes se heurtent à une complexité qui dépasse largement le simple développement. Résultat : des délais qui s’allongent, des coûts qui explosent, une fiabilité qui s’effondre.
En résumé : le MLOps est au machine learning ce que le DevOps est au développement logiciel, c'est-à-dire une approche structurée qui automatise les workflows, améliore la collaboration entre les équipes data science et d’ingénierie, et garantit la continuité des modèles en production.
En organisant tout le cycle de vie des modèles, de la conception à l’amélioration continue, le MLOps permet aux organisations de tirer un maximum de valeur de leurs projets d’IA et d’inscrire ces derniers dans la durée.
→ Essayez GitLab Ultimate et GitLab Duo Enterprise gratuitement.
Définition et rôle du MLOps
Le terme MLOps vient de la contraction de Machine Learning et Operations. Il désigne l’ensemble des pratiques, outils et méthodes qui permettent de gérer le cycle de vie complet des modèles de machine learning, depuis leur conception jusqu’à leur exploitation en production.
L’idée centrale est de rapprocher deux univers souvent séparés : celui des Data Scientists, qui développent et entraînent les modèles, et celui des équipes d'ingénierie, qui doivent les déployer, les surveiller et les maintenir. En créant ce lien, le MLOps assure une continuité entre l’expérimentation et l’utilisation réelle.
Son rôle dépasse donc la simple automatisation. Le MLOps vise à garantir la fiabilité des modèles dans le temps, à fluidifier la collaboration entre équipes et à donner aux organisations un cadre pour exploiter le machine learning de manière industrielle et durable.
Pourquoi le MLOps est-il devenu indispensable ?
Le machine learning s’est imposé bien au-delà de la recherche. Les cas d’usage se multiplient : détection de fraude en temps réel, recommandations personnalisées, maintenance prédictive, assistants génératifs. Ces modèles ne restent pas au stade expérimental : ils doivent tourner en production, souvent avec des exigences de latence strictes et sous des contraintes fortes.
Or, les difficultés apparaissent rapidement. Les cycles de déploiement s’allongent, les modèles se dégradent dès que les données évoluent, et les résultats deviennent difficiles à auditer. Sans optimisation, les coûts d’infrastructure s’envolent. Ces freins sont désormais bien connus des équipes.
Le MLOps apporte une réponse structurée à ces problèmes. Il standardise le déploiement, le suivi et la gouvernance des modèles. Il permet aussi de préparer l’avenir : intégrer l’AutoML, gérer des modèles génératifs, se conformer aux nouvelles réglementations comme l’AI Act (règlement européen sur l’intelligence artificielle).
Pour beaucoup d’organisations, l’adoption du MLOps marque une étape de maturité. Elle conditionne la capacité à transformer des prototypes en actifs pérennes et à inscrire l’IA dans une stratégie d’entreprise crédible.
Quels sont les avantages du MLOps ?
Le MLOps ne se résume pas à une méthode : c’est un changement de culture qui rend le machine learning plus rapide, plus fiable et plus scalable à chaque étape du cycle de vie du développement logiciel.
1. Des équipes enfin alignées
Le MLOps supprime les silos entre Data Scientists, développeurs et ingénieurs Ops. En partageant les mêmes pipelines et le même code source, chacun visualise les mêmes métriques et parle le même langage. Les modèles passent de la R&D à la production sans rupture ni perte d’information.
2. Un passage en production sans friction
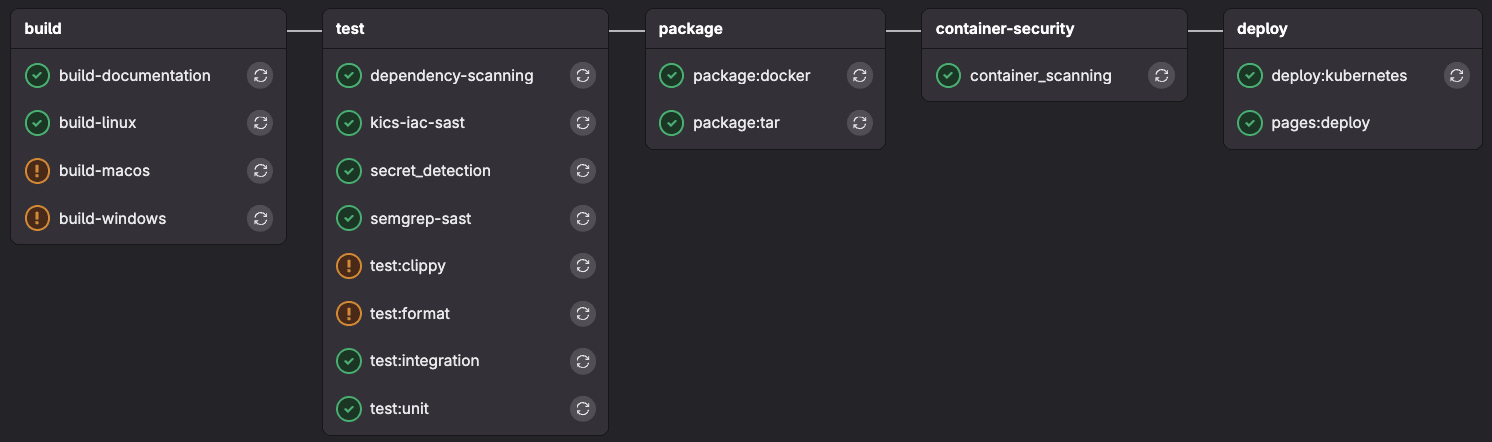
Grâce à l’automatisation CI/CD, les étapes d’entraînement, de test et de déploiement s’enchaînent sans intervention manuelle. Ce qui prenait des semaines se fait en quelques heures, avec des workflows reproductibles et contrôlés via des plateformes intégrées comme GitLab.
3. Des modèles traçables et reproductibles
Chaque version de modèle, de jeu de données et de code est archivée. En cas de dérive, il est possible de rejouer une expérience, d’identifier la cause ou de restaurer une version stable. Cette traçabilité transforme le machine learning en processus vérifiable et durable.
4. Une supervision continue en production
Le MLOps ne s’arrête pas au déploiement. Les performances sont surveillées en continu pour détecter les dérives. Des outils comme Prometheus ou Grafana peuvent être intégrés à GitLab afin d’alerter les équipes ou déclencher un réentraînement automatique.
5. Une gouvernance intégrée par conception
Le respect des exigences de sécurité, de conformité et d’auditabilité fait partie du pipeline. Documentation automatique, contrôle des accès et journaux d’audit garantissent la transparence et la conformité réglementaire sans effort supplémentaire.
Principes et bonnes pratiques du MLOps
Le MLOps ne se limite pas à des concepts. C’est aussi un ensemble de pratiques précises qui transforment un modèle expérimental en un service fiable et durable. Ces pratiques couvrent toute la chaîne logicielle : développement, déploiement, suivi et gouvernance.
Automatisation des workflows (CI/CD/CT)
Un projet de machine learning classique enchaîne plusieurs étapes répétitives :
-
Préparation des données
-
Entraînement
-
Tests
-
Packaging
-
Déploiement
Réalisées manuellement, elles s’avèrent lentes et fragiles. L’automatisation transforme ce parcours en une chaîne continue et prévisible.
Avec des pipelines CI/CD, chaque modification de code ou de données déclenche automatiquement les étapes nécessaires : entraînement, validation, déploiement. Les modèles passent en production plus vite, avec moins d’erreurs.
GitLab CI/CD, déjà largement adopté dans le développement logiciel, constitue un socle naturel pour orchestrer ces pipelines MLOps.
Le CT (Continuous Training) complète le CI/CD en automatisant le réentraînement des modèles. Dès qu'une dérive est détectée ou qu'un seuil de performance est franchi, un nouveau cycle d'entraînement peut être déclenché automatiquement. Cette pratique maintient les modèles alignés avec l'évolution des données sans intervention manuelle.
Exemple : ce fichier YAML minimaliste illustre un pipeline ML typique orchestré sur GitLab CI/CD :
-
Ingestion et préparation des données,
-
Entraînement et sauvegarde du modèle,
-
Tests et évaluation,
-
Déploiement automatisé en production.
image: python:3.9
before_script:
- pip install --no-cache-dir -r requirements.txt
stages:
- prepare
- train
- test
- deploy
prepare_data:
stage: prepare
script:
- python scripts/prepare_data.py
artifacts:
paths:
- data/processed/
expire_in: 7 days
train_model:
stage: train
script:
- python scripts/train.py --data data/processed/
artifacts:
paths:
- models/model.pkl
expire_in: 30 days
test_model:
stage: test
script:
- pytest tests/
- python scripts/evaluate.py models/model.pkl
deploy_model:
stage: deploy
script:
- bash scripts/deploy.sh models/model.pkl
when: on_success
Gestion des versions (données, modèles, code)
Sans gestion rigoureuse des versions, il est impossible de savoir sur quelles données un modèle a été entraîné ou de revenir à un état antérieur en cas de dérive.
Le MLOps généralise le versionnage systématique. Chaque jeu de données (dataset), chaque modèle et chaque pipeline est archivé et relié au code correspondant. GitLab, en s’appuyant sur Git, apporte cette logique de gestion des versions nativement. Étendue aux workflows ML, elle garantit une traçabilité complète de bout en bout.
Note : le registre de modèles de GitLab permet de versionner et de cataloguer les modèles ML aux côtés du code source, créant ainsi une source unique de vérité pour l'ensemble du projet.
Validation et qualité des données et modèles
Un modèle performant dans un environnement de test peut échouer en production. Pour éviter ce décalage, le MLOps introduit des validations à plusieurs niveaux.
-
Qualité des données : détection des valeurs aberrantes, cohérence entre jeux d’entraînement et de validation, suivi de la complétude.
-
Robustesse des modèles : tests de performance, vérification des biais, évaluation sur des scénarios métiers représentatifs.
Ces contrôles intégrés dans le pipeline réduisent le risque de déployer des modèles fragiles ou biaisés.
Monitoring et détection de la dérive
Un modèle n’est jamais figé. Les données évoluent, les comportements changent, et ses performances se dégradent avec le temps.
Le MLOps intègre un monitoring continu des métriques techniques et métiers. Il détecte les dérives statistiques, génère des alertes et peut même déclencher un réentraînement automatisé. Cette boucle prolonge la durée de vie des modèles et maintient leur alignement avec les besoins opérationnels.
Ingénierie des données
Beaucoup de projets échouent non pas à cause des modèles, mais à cause de données instables ou mal structurées. C’est pourquoi l’ingénierie des données est une composante essentielle du MLOps.
Elle repose sur plusieurs pratiques : définir des contrats de données clairs entre ceux qui produisent et ceux qui utilisent les données, surveiller en continu la qualité et la disponibilité des flux de données, et choisir le bon mode de traitement - batch pour les volumes massifs, streaming pour le temps réel. Ces fondations garantissent que les modèles s’appuient sur des données fiables et stables.
Un composant clé de cette démarche est le Feature Store, qui centralise et versionne les caractéristiques (features) utilisées par les modèles. Il garantit la cohérence entre l'entraînement et la production, évite la duplication et accélère le développement de nouveaux modèles.
LLMOps pour les modèles génératifs
Au-delà des modèles traditionnels, les modèles génératifs introduisent des défis inédits : prompts évolutifs, coûts d’inférence élevés, évaluation de la qualité plus complexe.
Le LLMOps transpose les principes du MLOps à ce contexte. Il inclut la gestion des versions de prompts, l’intégration des retours utilisateurs et le suivi détaillé des coûts d’exécution. Dans certains environnements, une seule application peut générer des coûts d’inférence de plusieurs milliers d’euros par jour : garder la maîtrise de ces dépenses devient un impératif stratégique.
Cycle de vie d’un projet MLOps
Le MLOps ne se résume pas à des principes. C’est avant tout une manière d’organiser le cycle de vie d’un projet de machine learning, depuis la préparation des données jusqu’à l’amélioration continue en production. Chaque étape est reliée aux autres et gagne en efficacité grâce à une approche structurée.
Collecte et préparation des données
La donnée est le point de départ de tout projet de machine learning. Pourtant, elle est aussi l’une de ses principales sources de difficulté. Plusieurs études montrent que la préparation des données peut mobiliser entre 50 % et 80 % du temps des Data Scientists, selon la qualité des sources et le degré d’automatisation disponible.
Le MLOps formalise ce travail avec des pipelines d’ingestion automatisés, des contrats de données entre équipes et des validations systématiques (complétude, cohérence, détection d’anomalies). Ces mécanismes réduisent les erreurs et sécurisent les étapes suivantes.
Cette base solide optimise les étapes d’entraînement avec les meilleures conditions possibles.
Entraînement des modèles
Une fois les données prêtes, l’objectif n’est pas seulement d’obtenir de bonnes métriques mais aussi de garantir la reproductibilité des résultats.
Le MLOps renforce cette étape avec deux leviers :
-
le versionnage systématique des données, du code et des modèles ;
-
l’automatisation des expériences via des pipelines.
Chaque essai est documenté, chaque paramètre enregistré. Les équipes peuvent comparer objectivement les résultats et identifier rapidement les configurations les plus prometteuses.
Mise en production
Un modèle performant en environnement de développement n’a pas d’impact tant qu’il n’est pas utilisé. La mise en production est donc une étape clé, mais souvent la plus délicate.
Le MLOps simplifie ce passage grâce à l’automatisation : packaging standardisé, tests intégrés, déploiement reproductible. Là où une mise en production pouvait nécessiter plusieurs semaines de coordination, elle peut désormais être réalisée en quelques jours.
Là encore, GitLab CI/CD offre une base solide pour orchestrer ces déploiements continus, en s’appuyant sur des outils déjà familiers aux équipes DevOps.
Suivi des performances et amélioration continue
Une fois en ligne, le modèle est confronté à des données vivantes. Ses performances évoluent, parfois à la baisse.
Certaines équipes dépassent le simple monitoring en implémentant un réentraînement automatisé dès qu’un seuil de dégradation des performances est franchi. Cette boucle d’amélioration continue assure que le modèle reste pertinent et aligné avec les besoins du métier.
Les rôles dans un projet MLOps
Un projet MLOps ne repose pas sur une seule équipe mais sur la complémentarité de plusieurs profils. Chacun joue un rôle clé dans la conception, le déploiement et la maintenance des modèles.
Data Scientists
Les Data Scientists restent les architectes des modèles. Leur rôle est d’explorer les données, de concevoir les algorithmes et de tester différentes approches. Ils définissent aussi les métriques qui guideront l’évaluation des performances.
Dans une démarche MLOps, leur mission évolue. Les notebooks deviennent reproductibles, les scripts s’intègrent dans des pipelines, et les modèles sont versionnés. Ce changement de cadre évite que leurs travaux ne restent bloqués au stade de prototype et facilite leur passage en production.
Data Engineers et équipes DevOps
Les modèles n’ont de valeur que s’ils peuvent être exploités. Les Data Engineers et les équipes DevOps jouent un rôle central pour transformer les expérimentations en solutions robustes.
-
Les Data Engineers construisent et maintiennent les pipelines d’ingestion, s’assurent de la qualité et de la disponibilité des flux de données, et posent les fondations de la gouvernance des données.
-
Les équipes DevOps orchestrent les déploiements, automatisent les tests et surveillent les environnements. Elles appliquent au machine learning les pratiques qui ont déjà révolutionné le développement logiciel : le CI/CD, le monitoring, la gestion des accès.
Avec des plateformes comme GitLab, ces équipes disposent d’outils déjà éprouvés pour intégrer leurs workflows MLOps sans multiplier les outils et plateformes.
Coordination avec les équipes métiers
Un modèle ne se juge pas seulement à la précision de ses prédictions. Il doit aussi générer un impact visible pour l’organisation. C’est là que les équipes métiers entrent en jeu.
Elles définissent les indicateurs clés de succès, apportent leur expertise terrain et valident la pertinence des modèles dans des contextes concrets. Dans une démarche MLOps, cette collaboration devient permanente plutôt que ponctuelle. Les retours alimentent l’évaluation, influencent les priorités et guident les décisions de réentraînement.
Sans cette boucle de validation, même un modèle techniquement performant peut manquer sa cible et échouer à apporter de la valeur réelle.
Quelles sont les erreurs fréquentes à éviter ?
Même avec une démarche MLOps structurée, certains écueils reviennent régulièrement. Ils ralentissent les projets et compromettent leur valeur en production.
Trop d’outils sans cadre clair
Utiliser des outils spécialisés peut sembler une bonne idée : un pour l’ingestion, un autre pour l’entraînement, un troisième pour le monitoring, etc. Mais à mesure que la pile technologique s’étoffe, la complexité explose. Les coûts augmentent et la visibilité se réduit.
Le MLOps repose au contraire sur une vision unifiée. Les pipelines doivent s’appuyer sur des briques cohérentes, idéalement regroupées au sein de plateformes intégrées comme GitLab, qui limitent la fragmentation et assurent une traçabilité de bout en bout.
Absence de métriques métiers
Un modèle peut obtenir de très bons scores techniques tout en restant inutile pour l’organisation. L’absence d’indicateurs métiers conduit à déployer des modèles performants en apparence, mais déconnectés des besoins réels. Le suivi des métriques business (taux de fraude détecté, satisfaction client, temps de traitement gagné) doit compléter les métriques classiques du machine learning.
Données instables et dette technique
Sans pipelines de données robustes, les modèles héritent de jeux instables ou non représentatifs. À court terme, cela crée des résultats imprévisibles. À long terme, la multiplication des correctifs génère une dette technique qui alourdit chaque évolution. Le MLOps impose des pratiques d’ingénierie des données et une supervision continue pour maintenir des flux de données fiables et éviter cet effet boule de neige.
MLOps vs DevOps : quelles différences ?
Le MLOps s’inspire directement de l’approche DevOps. Les deux disciplines partagent une même philosophie : rapprocher le développement et les opérations, réduire les délais et fiabiliser les déploiements grâce à l’automatisation. Mais leurs applications divergent dès que l’on touche aux modèles de machine learning.
Points communs
Les deux approches reposent sur la même boîte à outils : pipelines CI/CD, monitoring et gestion des versions. Dans les deux cas, le but reste identique : livrer rapidement des artefacts fiables en production.
Ce qui les différencie
La différence fondamentale vient de la nature des artefacts. En DevOps, nous déployons des applications statiques. En MLOps, nous déployons des modèles issus de données mouvantes.
Cette spécificité entraîne cinq conséquences majeures :
-
nécessité de versionner des données et des modèles, pas seulement le code ;
-
intégration de validations métiers en plus des tests techniques ;
-
surveillance continue des performances, car un modèle se dégrade dans le temps ;
-
nature expérimentale : le même code peut produire des résultats différents selon les données et les paramètres utilisés, nécessitant un tracking systématique de chaque expérience ;
-
optimisation itérative des hyperparamètres (learning rate, architecture, etc.) qui doivent être explorés, comparés et versionnés pour identifier la meilleure configuration.
La place du MLOps par rapport à DataOps et ModelOps
Le MLOps ne vit pas en vase clos. Il se situe à la croisée de deux autres disciplines : le DataOps, centré sur la qualité et la gouvernance des données, et le ModelOps, focalisé sur la gestion et le déploiement des modèles.
En combinant ces deux dimensions, le MLOps prend en charge l’ensemble du cycle : de la fiabilité des données jusqu’à l’industrialisation des modèles.
Tendances à suivre
Le MLOps évolue rapidement, porté par l’industrialisation de l’IA et l’émergence de nouvelles contraintes techniques et réglementaires. Plusieurs tendances structurent déjà les pratiques des prochaines années.
Serverless MLOps et MLOps distribué
L’adoption croissante du serverless simplifie l’exécution des pipelines ML : les ressources s’adaptent automatiquement à la charge, réduisant coûts et complexité. Parallèlement, le MLOps distribué à la périphérie (edge) prend de l’ampleur, notamment dans l’IoT et les applications embarquées. Les modèles s’exécutent directement au plus près des données, avec moins de latence et plus de réactivité.
Nouvelles exigences de gouvernance et de régulation
Avec l’AI Act européen entré en vigueur en 2024, la conformité devient un enjeu stratégique. Les organisations doivent prouver la traçabilité, l’explicabilité et la robustesse de leurs modèles. Le MLOps devient un levier essentiel pour intégrer dès aujourd’hui ces obligations, plutôt que de subir des blocages lors d’un audit ou d’un lancement produit.
Ressources et outils pratiques
Le MLOps ne s’arrête pas aux concepts. Il prend forme dans des workflows, des métriques et des règles de gouvernance que les équipes peuvent mettre en œuvre dans leurs projets.
Checklist pour lancer un pipeline MLOps
Mettre en place un pipeline MLOps ne s’improvise pas. Voici une checklist pour démarrer dans de bonnes conditions :
-
Définir les objectifs métiers et les indicateurs clés de performance (KPI) ;
-
Préparer des pipelines de données avec des règles de validation automatisées ;
-
Versionner le code, les données et les modèles ;
-
Intégrer entraînement, tests et déploiement dans une chaîne CI/CD ;
-
Prévoir un monitoring continu des performances et de la dérive ;
-
Documenter et suivre chaque étape pour la gouvernance et la conformité.
Exemples de métriques à suivre en production
Un modèle ne peut être piloté sans indicateurs. Les métriques à surveiller couvrent à la fois les aspects techniques et métiers :
-
Aspects techniques : précision, rappel, F1-score, latence, taux d’erreur ;
-
Aspects métiers : taux de fraude détectée, réduction des coûts opérationnels, satisfaction client ;
-
Aspects opérationnels : consommation de ressources, coût par prédiction, empreinte énergétique.
Le suivi de ces métriques permet d’anticiper la dérive, d’ajuster les modèles et de prouver leur valeur ajoutée.
Conclusion : l’importance du MLOps pour industrialiser l’IA
De nombreux projets de machine learning échouent non pas à cause des modèles eux-mêmes, mais parce qu’ils ne franchissent pas le cap de la production. Trop souvent, ils restent confinés aux notebooks, difficiles à maintenir et incapables de s’adapter à des données changeantes. Le MLOps est né pour combler cet écart.
En automatisant les étapes critiques, en assurant la traçabilité des données et des modèles et en intégrant un suivi continu, il transforme des expérimentations isolées en actifs durables. Il ne s’agit plus seulement de tester une idée, mais de bâtir un système capable de créer de la valeur au fil du temps.
L’adoption du MLOps n'est pas qu'une approche technique : c’est un levier stratégique. Il accélère le passage de l’expérimentation au déploiement, réduit les coûts d’itération et donne aux métiers la confiance nécessaire pour utiliser l’IA à grande échelle.
Pour aller plus loin, les organisations ont besoin d’outils qui favorisent cette approche intégrée. Des plateformes comme GitLab, déjà au cœur des pratiques DevOps, offrent une base solide pour orchestrer les pipelines, gérer les versions et rapprocher les équipes. Le MLOps devient alors non seulement une méthode, mais une infrastructure de confiance pour industrialiser l’intelligence artificielle.
GitLab, un socle naturel pour le MLOps
Mettre en œuvre une démarche MLOps ne consiste pas à accumuler des outils, mais à créer une chaîne cohérente reliant développement, données et production. GitLab offre précisément cette continuité : un environnement unique où les équipes peuvent versionner le code, orchestrer les pipelines CI/CD, monitorer les modèles et documenter chaque étape du cycle de développement logiciel. En intégrant les pratiques MLOps dans une plateforme déjà familière aux équipes DevOps, les organisations évitent la complexité d’une infrastructure fragmentée et accélèrent la transformation de leurs projets de machine learning en solutions opérationnelles.
FAQ sur le MLOps
Quelle est la différence entre MLOps et DevOps ?
Le DevOps s’applique au développement logiciel classique, où l’artefact final est une application statique. Le MLOps reprend cette logique d’automatisation et de collaboration, mais l’adapte aux spécificités du machine learning. La différence majeure : un modèle n’est pas seulement du code, c’est aussi des données qui évoluent dans le temps. Le MLOps ajoute donc le versionnage des jeux de données (datasets) et des modèles, la validation métier et le suivi continu des performances.
Quels outils utiliser pour mettre en place le MLOps ?
Un écosystème varié existe : plateformes de CI/CD, solutions de monitoring, outils de versioning de données ou de gestion de modèles. L’enjeu est moins d’accumuler des briques que d’assurer leur intégration. Des plateformes comme GitLab, déjà adoptées pour le DevOps et le DevSecOps, offrent une base unifiée qui facilite l’automatisation, la collaboration et la traçabilité dans un cadre MLOps.
Comment gérer la dérive d’un modèle en production ?
La dérive survient lorsque les données en production ne ressemblent plus à celles utilisées pour l’entraînement, entraînant une baisse de performance. Le MLOps prévoit un monitoring continu des métriques, des alertes en cas d’écart et parfois des mécanismes de réentraînement automatique. La clé est de définir dès le départ les seuils critiques et les métriques métiers à surveiller.
Comment mesurer le succès d’une démarche MLOps ?
Le succès ne se limite pas aux performances techniques des modèles. Il se mesure aussi par :
-
La réduction du temps nécessaire pour passer de l’expérimentation à la production ;
-
La stabilité et la traçabilité des modèles déployés ;
-
L’impact métier réel, via des indicateurs comme le gain de productivité, la baisse des coûts ou l’amélioration de l’expérience client.
Une démarche MLOps réussie combine donc efficacité opérationnelle et création de valeur mesurable.
]]>→ Essayez GitLab Ultimate et GitLab Duo Enterprise gratuitement.