Software-Entwicklungsteams sind mit einer Informationsflut konfrontiert. Tausende Schwachstellen überschwemmen Security-Dashboards, aber nur ein Bruchteil stellt ein echtes Risiko dar. Entwickler wechseln zwischen Backlog-Planung, Triage von Security-Findings, Code-Reviews und der Reaktion auf CI/CD-Fehler hin und her – und verlieren dabei Stunden durch manuelle Arbeit. GitLab 18.5 bringt Struktur in diese Komplexität.
Im Mittelpunkt dieses Release steht eine wesentliche Verbesserung der allgemeinen Usability von GitLab und der Integration von KI in die User Experience. Ein neues Panel-basiertes UI erleichtert die kontextbezogene Darstellung von Daten und ermöglicht es, GitLab Duo Chat plattformübergreifend dauerhaft sichtbar zu halten, wo immer es benötigt wird. Spezialisierte Agenten übernehmen die Triage von Schwachstellen und das Backlog-Management, während sich beliebte KI-Tools noch nahtloser in agentenbasierte Workflows integrieren lassen. Zusätzlich wurden die marktführenden Sicherheitsfunktionen erweitert, um ausnutzbare Schwachstellen besser von theoretischen zu unterscheiden, aktive von abgelaufenen Credentials zu trennen und nur geänderten Code zu scannen, damit Entwickler im Flow bleiben können.
Was ist neu in 18.5
18.5 ist das bisher größte Release dieses Jahres – die Einführung in das Release im Video ansehen und weitere Details unten lesen.
<div style="padding:56.25% 0 0 0;position:relative;"><iframe src="https://player.vimeo.com/video/1128975773?badge=0&autopause=0&player_id=0&app_id=58479" frameborder="0" allow="autoplay; fullscreen; picture-in-picture; clipboard-write; encrypted-media; web-share" referrerpolicy="strict-origin-when-cross-origin" style="position:absolute;top:0;left:0;width:100%;height:100%;" title="GitLab_18.5 Release_101925_MP_v2"></iframe></div><script src="https://player.vimeo.com/api/player.js"></script>
<p></p>
Moderne User Experience mit schnellem Zugriff auf GitLab Duo überall
GitLab 18.5 liefert eine modernisierte User Experience mit einem intuitiveren Interface, das auf einem neuen Panel-basierten Layout basiert.
Panels zeigen wichtige Informationen nebeneinander an, sodass sich kontextbezogen arbeiten lässt, ohne die Position zu verlieren. Wenn beispielsweise auf ein Issue in der Issue-Liste geklickt wird, öffnen sich die Details automatisch in einem Side Panel. Das GitLab Duo Panel lässt sich rechts öffnen und bringt Duo an jeden Ort in GitLab. So können kontextbezogene Fragen gestellt oder Anweisungen gegeben werden, direkt neben der eigentlichen Arbeit.
Mehrere Usability-Verbesserungen erleichtern die Navigation. Die globale Suchleiste erscheint nun in der oberen Mitte für bessere Zugänglichkeit. Globale Navigationselemente wie Issues, Merge Requests, To-Dos und der Avatar sind in die obere rechte Ecke gewandert. Zusätzlich lässt sich die linke Sidebar nun ein- und ausklappen für mehr Kontrolle über den Workspace.
Teams, die experimentelle Features und GitLab Duo Beta-Features nutzen, erhalten das neue Interface zuerst. Danach können alle GitLab.com-Nutzer diese Experience über einen Toggle aktivieren, der sich unter dem User-Icon befindet. Mehr Details zu diesem Feature in der Dokumentation. Feedback oder Issues können gemeldet werden – damit lässt sich GitLab besser gestalten!
Neuerungen zur GitLab Duo Agent Platform
Security Analyst Agent: Von manueller Vulnerability-Triage zu intelligenter Automatisierung
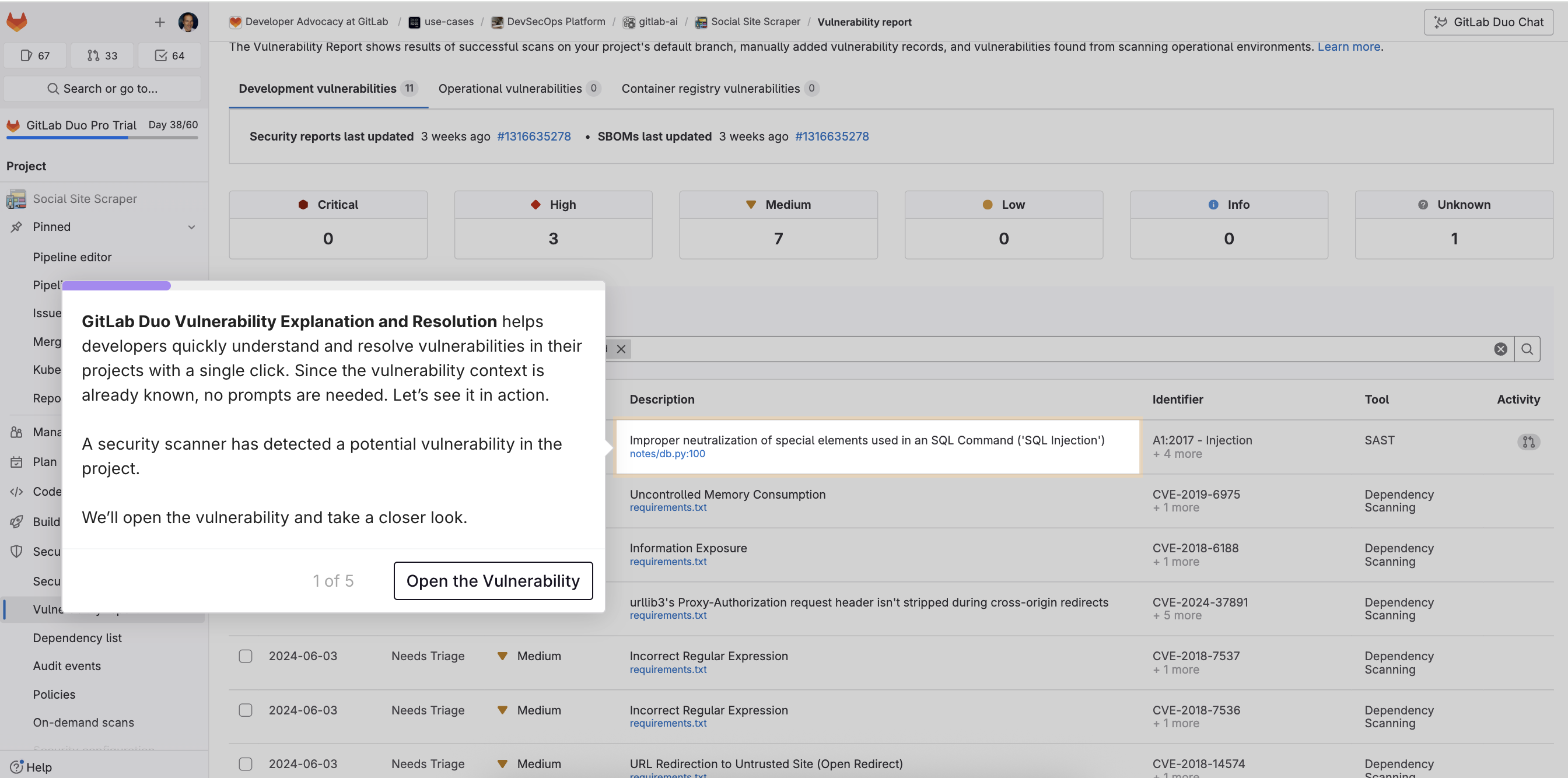
Der GitLab Duo Security Analyst Agent automatisiert Vulnerability-Management-Workflows durch KI-gestützte Analyse und verwandelt stundenlanges manuelles Triaging in intelligente Automatisierung. Aufbauend auf den Vulnerability Management Tools, die über GitLab Duo Agentic Chat verfügbar sind, orchestriert der Security Analyst Agent mehrere Tools, wendet Sicherheitsrichtlinien an und erstellt automatisch benutzerdefinierte Flows für wiederkehrende Workflows.
Sicherheitsteams erhalten Zugriff auf angereicherte Vulnerability-Daten, einschließlich CVE-Details, statischer Erreichbarkeitsanalyse und Informationen zum Code-Fluss. Sie können Operationen wie das Verwerfen von Fehlalarmen, das Bestätigen von Bedrohungen, das Anpassen von Schweregraden und das Erstellen verknüpfter Issues zur Behebung ausführen: alles über Conversational AI. Der Agent reduziert repetitives Klicken durch Vulnerability-Dashboards und ersetzt Custom Scripts durch einfache Befehle in natürlicher Sprache.
Beispiel: Wenn ein Security-Scan Dutzende Schwachstellen aufdeckt, genügt der Prompt: „Dismiss vulnerabilities with reachable=FALSE and create issues for critical findings." Der Security Analyst Agent analysiert Erreichbarkeitsdaten, wendet Sicherheitsrichtlinien an und erledigt Massenoperationen in Momenten – Arbeit, die sonst Stunden dauern würde.
Während einzelne Vulnerability Management Tools direkt über Agentic Chat für spezifische Aufgaben zugänglich sind, orchestriert der Security Analyst Agent diese Tools intelligent und automatisiert komplexe mehrstufige Workflows. Die Vulnerability Management Tools sind über Agentic Chat auf GitLab Self-managed und GitLab.com verfügbar, der Security Analyst Agent ist in 18.5 nur auf GitLab.com verfügbar. Die Verfügbarkeit in Self-managed- und Dedicated-Umgebungen folgt mit dem nächsten Release.
Demo ansehen:
<div style="padding:56.25% 0 0 0;position:relative;"><iframe src="https://player.vimeo.com/video/1128975984?badge=0&autopause=0&player_id=0&app_id=58479" frameborder="0" allow="autoplay; fullscreen; picture-in-picture; clipboard-write; encrypted-media; web-share" referrerpolicy="strict-origin-when-cross-origin" style="position:absolute;top:0;left:0;width:100%;height:100%;" title="18.5 Security Demo"></iframe></div><script src="https://player.vimeo.com/api/player.js"></script>
<p></p>
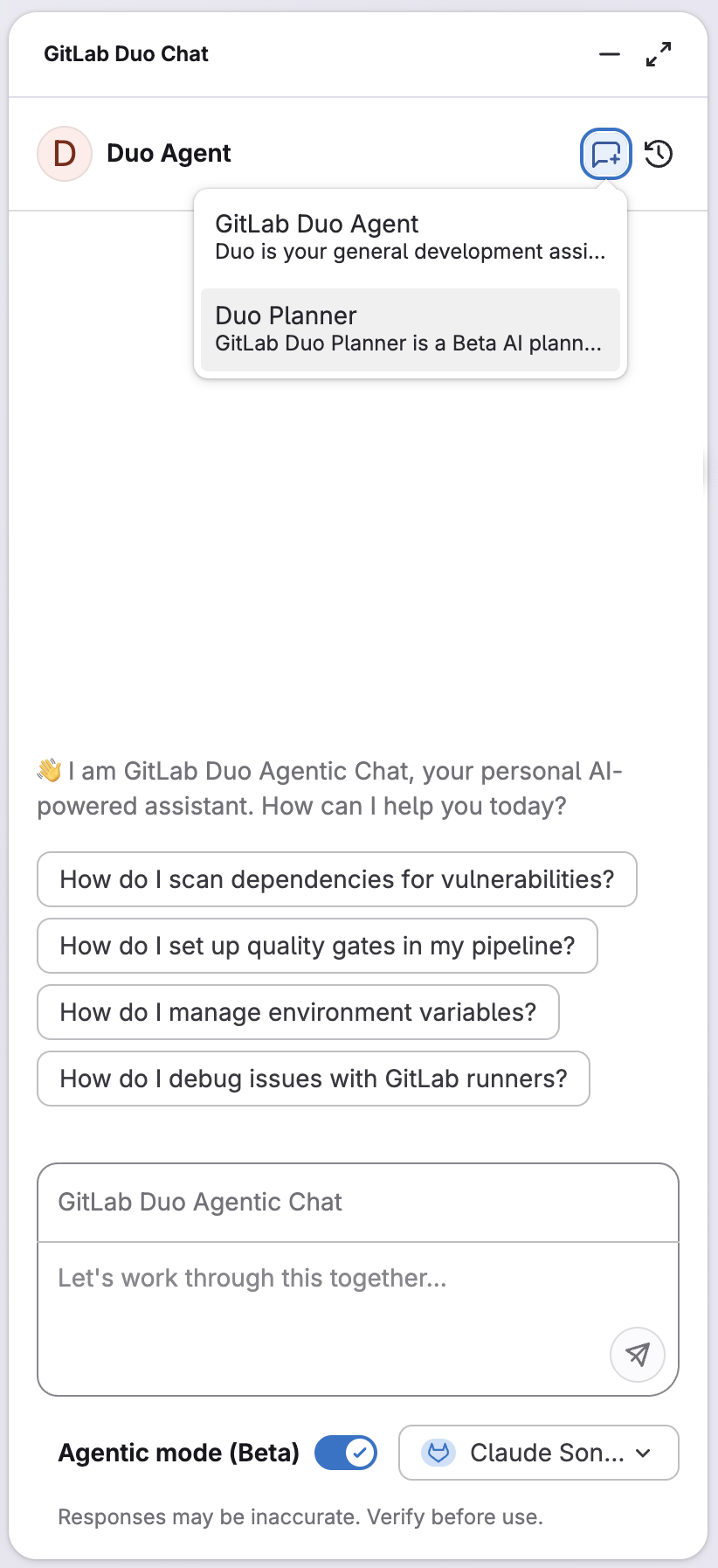
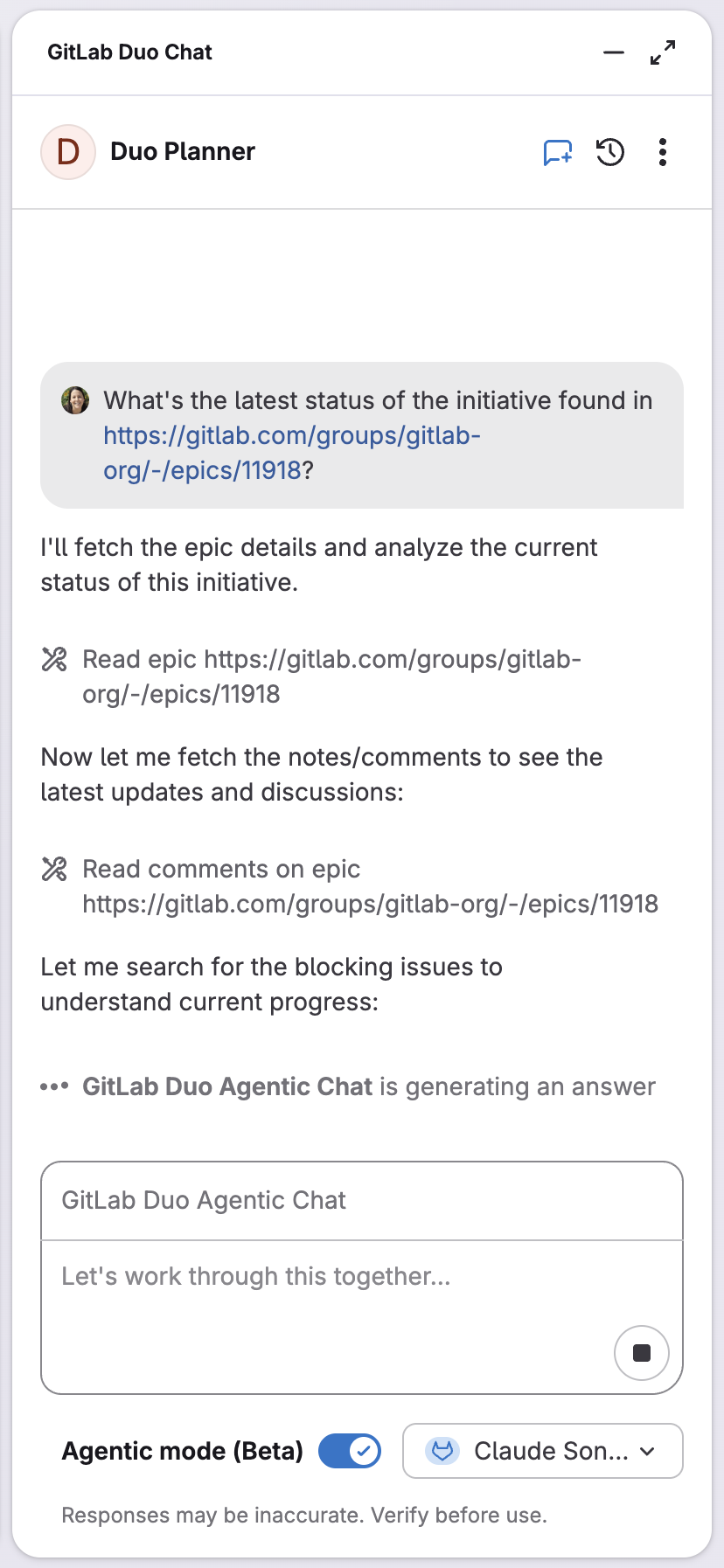
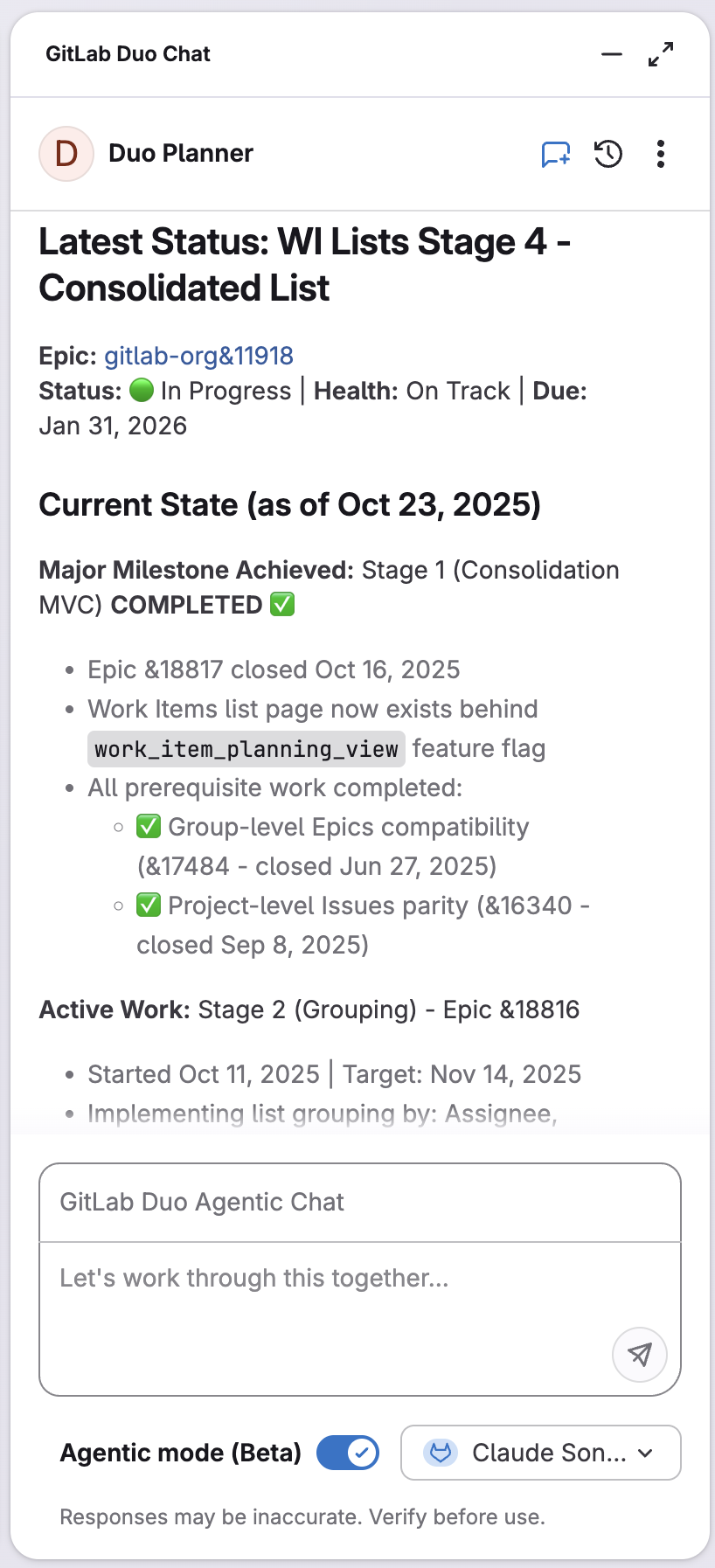
GitLab Duo Planner: Von Backlog-Chaos zu strategischer Klarheit
Die Verwaltung komplexer Software-Delivery erfordert ständige Kontextwechsel zwischen Planungsaufgaben. GitLab Duo Planner adressiert die realen Planungsherausforderungen, mit denen Teams täglich konfrontiert sind. Duo Planner agiert als Teammitglied mit Bewusstsein für den Projektkontext. Er versteht, wie Issues, Epics und Merge Requests verwaltet werden. Anders als generische KI-Assistenten ist er speziell konzipiert mit tiefem Wissen über GitLabs Planungs-Workflows, kombiniert mit Agile- und Priorisierungs-Frameworks, um Aufwand, Risiko und strategische Ausrichtung auszubalancieren.
GitLab Duo Planner kann vage Ideen in strukturierte Planungshierarchien verwandeln, veraltete Backlog-Items identifizieren und Executive Updates entwerfen. Beispiel: Beim Verfeinern eines Backlogs mit Hunderten über Monate angesammelten Issues genügt der Prompt: „Identify stale backlog items and suggest priorities." Innerhalb von Sekunden erhält man eine strukturierte Zusammenfassung mit Issues ohne aktuelle Aktivität, Items mit fehlenden Details, doppelter Arbeit und empfohlenen Prioritäten basierend auf Labels und Milestones – komplett mit umsetzbaren Empfehlungen.
Für Teams, die komplexe Roadmaps verwalten, zielt der Planner darauf ab, Stunden manueller Analyse und Kontextwechsel zu eliminieren und Product Managern sowie Engineering Leads zu helfen, schnellere und besser informierte Entscheidungen zu treffen. Ab 18.5 ist GitLab Duo Planner aktuell schreibgeschützt, das heißt, er kann analysieren, planen und vorschlagen, aber noch keine direkten Aktionen zur Änderung ausführen. Weitere Informationen in der Dokumentation.
Extensible Agent Catalog: Beliebte KI-Tools als native GitLab-Agenten
GitLab 18.5 führt beliebte KI-Agenten direkt in den AI Catalog ein und macht externe Tools wie Claude, OpenAI Codex, Google Gemini CLI, Amazon Q Developer und OpenCode als native GitLab-Agenten verfügbar. Nutzer können diese Agenten nun über dieselbe einheitliche Catalog-Oberfläche entdecken, konfigurieren und deployen, die auch für GitLabs integrierte Agenten verwendet wird. Foundational Agents werden automatisch über Organisations-Catalogs hinweg synchronisiert.
Dies eliminiert die Komplexität des manuellen Agent-Setups durch eine grafische Katalog-Oberfläche und behält dabei Sicherheit auf Enterprise-Niveau durch GitLabs Authentifizierungs- und Audit-Systeme bei. GitLab Duo Enterprise Subscriptions enthalten nun die integrierte Nutzung von Claude und Codex innerhalb von GitLab, sodass die bestehende GitLab-Subscription für diese Tools verwendet werden kann, ohne separate API-Keys oder zusätzliches Billing-Setup zu benötigen. Andere Agenten können weiterhin separate Subscriptions und Konfiguration erfordern, während die Integrationspläne finalisiert werden.
Self-hosted GitLab Duo Agent Platform (Beta): Anforderungen an Datensouveränität erfüllen, ohne auf KI-Power zu verzichten
GitLab 18.5 hebt die Self-hosted-Funktionen der GitLab Duo Agent Platform von experimental auf beta und ermöglicht es Organisationen, KI-Agenten und Flows vollständig innerhalb ihrer eigenen Infrastruktur auszuführen – entscheidend für regulierte Branchen und Datensouveränitätsanforderungen. Das Beta-Release umfasst verbesserte Timeout-Konfigurationen und AI-Gateway-Einstellungen und erlaubt Teams, KI-Agenten für Code-Reviews, Bug-Fixes und Feature-Implementierungen zu nutzen, während Sicherheit auf Enterprise-Niveau für sensiblen Code gewährleistet wird.
Intelligentere, schnellere Sicherheit: Echte Risiken priorisieren und Entwickler im Flow halten
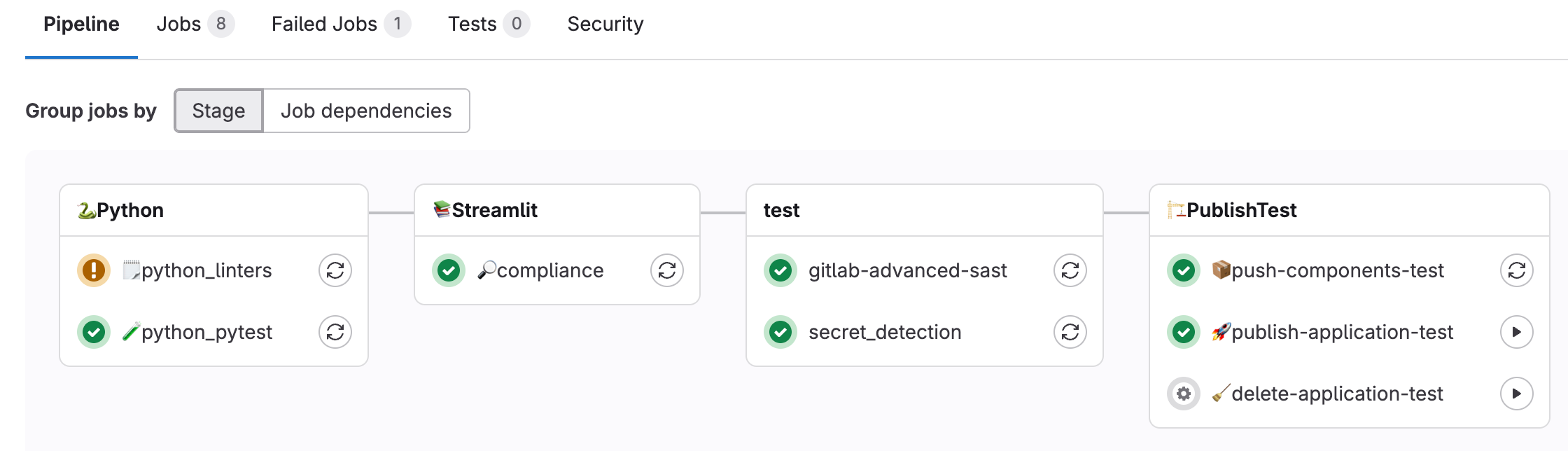
GitLab 18.5 führt neue Application-Security-Funktionen ein, die Teams helfen, ausnutzbare Risiken zu fokussieren, Rauschen zu reduzieren und die Software-Supply-Chain-Sicherheit zu stärken. Diese Updates setzen das Commitment fort, Sicherheit direkt in den Entwicklungsprozess zu integrieren – mit Präzision, Geschwindigkeit und Einblicken, ohne den Arbeitsfluss der Entwickler zu unterbrechen.
Statische Erreichbarkeitsanalyse
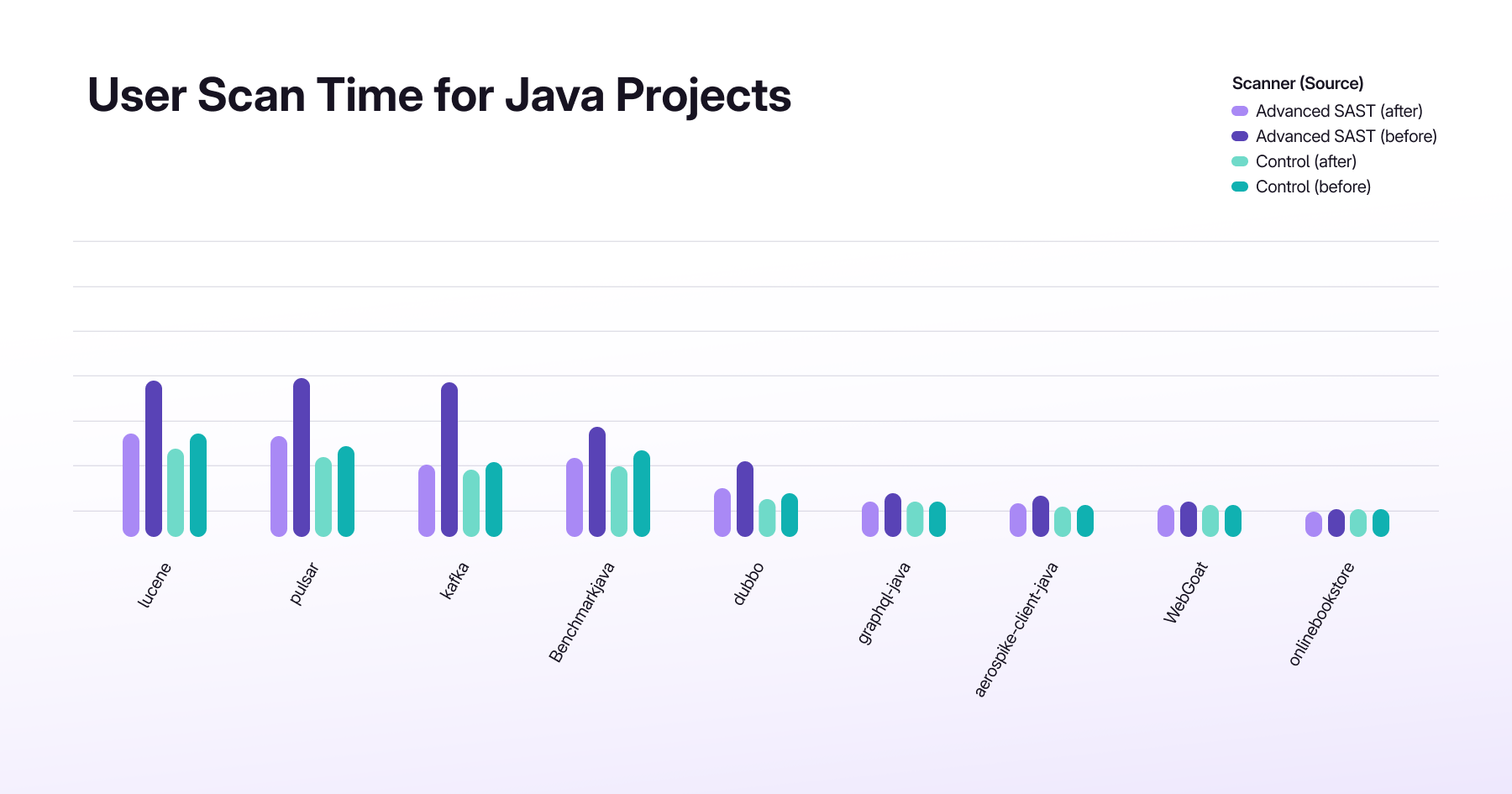
Mit über 37 000 neuen CVEs allein in diesem Jahr stehen Sicherheitsteams vor einem überwältigenden Volumen an Schwachstellen und haben Schwierigkeiten zu verstehen, welche davon tatsächlich ausnutzbar sind. Die statische Erreichbarkeitsanalyse, jetzt in Limited Availability, bringt Präzision auf Bibliotheksebene, indem sie hilft zu identifizieren, ob verwundbarer Code tatsächlich in der Anwendung aufgerufen wird und nicht nur in Abhängigkeiten vorhanden ist.
In Kombination mit dem kürzlich veröffentlichten Exploit Prediction Scoring System (EPSS) und Known Exploited Vulnerability (KEV) Daten können Sicherheitsteams die Vulnerability-Triage effektiver beschleunigen. So lassen sich echte Risiken priorisieren und die gesamte Sicherheit der Lieferkette stärken. In 18.5 kommt Unterstützung für Java hinzu, neben der bestehenden Unterstützung für Python, JavaScript und TypeScript.
Validierung exponierter Secrets
Genau wie die statische Erreichbarkeitsanalyse Teams hilft, ausnutzbare Schwachstellen aus Open-Source-Abhängigkeiten zu priorisieren, bringen Secret Validity Checks denselben Einblick für exponierte Secrets – aktuell in Beta auf GitLab.com und GitLab Self-Managed verfügbar. Für von GitLab ausgestellte Security-Tokens unterscheidet GitLab automatisch aktive von abgelaufenen Secrets direkt im Vulnerability Report, anstatt manuell zu prüfen, ob ein geleakter Credential oder API-Key aktiv ist. Dies ermöglicht es Sicherheits- und Entwicklungsteams, Remediation-Maßnahmen auf echte Risiken zu fokussieren. Unterstützung für von AWS und GCP ausgestellte Secrets ist für zukünftige Releases geplant.
Benutzerdefinierte Regeln für Advanced SAST
Advanced SAST läuft auf Regeln, die vom hauseigenen Security-Research-Team entwickelt wurden, um maximale Genauigkeit out of the box zu bieten. Einige Teams benötigten jedoch zusätzliche Flexibilität, um die SAST-Engine für ihre spezifische Organisation anzupassen. Mit benutzerdefinierten Regeln für Advanced SAST können AppSec-Teams atomare, musterbasierte Erkennungslogik definieren, um organisationsspezifische Sicherheitsprobleme zu erfassen – etwa das Flaggen verbotener Funktionsaufrufe – während GitLabs kuratiertes Ruleset weiterhin als Baseline dient. Anpassungen werden über einfache TOML-Dateien verwaltet, genau wie andere SAST-Ruleset-Konfigurationen. Diese Regeln unterstützen zwar keine Taint Analysis, bieten Organisationen aber größere Flexibilität für präzise SAST-Ergebnisse.
Advanced SAST: Unterstützung für C und C++
Die Sprachabdeckung für Advanced SAST wird um C und C++ erweitert, die in der Embedded-Systems-Softwareentwicklung weit verbreitet sind. Um das Scannen zu aktivieren, müssen Projekte eine Compilation Database generieren, die Compiler-Befehle und Include-Pfade erfasst, die während Builds verwendet werden. Dies stellt sicher, dass der Scanner Quelldateien präzise parsen und analysieren kann und kontextbewusste Ergebnisse liefert, die Sicherheitsteams helfen, echte Schwachstellen im Entwicklungsprozess zu identifizieren. Die Implementierungsanforderungen für C und C++ erfordern spezifische Konfigurationen, die in der Dokumentation zu finden sind. Advanced SAST C- und C++-Unterstützung sind aktuell in Beta verfügbar.
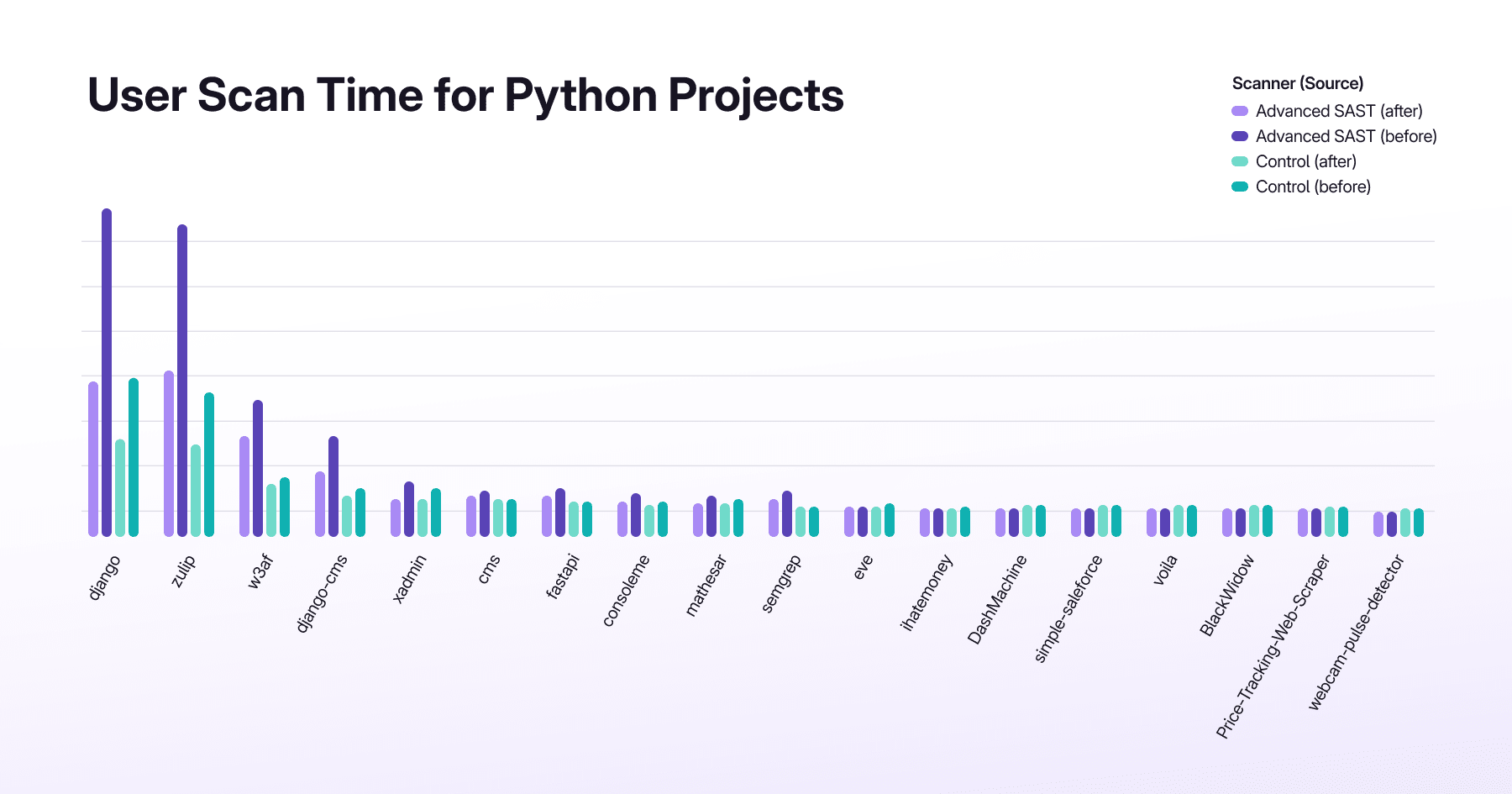
Diff-basiertes SAST-Scanning
Traditionelle SAST-Scans analysieren mit jedem Commit die gesamte Codebase neu, verlangsamen Pipelines und unterbrechen den Arbeitsfluss der Entwickler. Die Developer Experience ist eine entscheidende Überlegung, die über die Adoption von Application Security Testing entscheiden kann. Diff-basiertes SAST-Scanning zielt darauf ab, Scan-Zeiten zu beschleunigen, indem nur der in einem Merge Request geänderte Code fokussiert wird, redundante Analysen reduziert werden und relevante Ergebnisse angezeigt werden, die mit der Arbeit des Entwicklers verknüpft sind. Durch die Ausrichtung der Scans auf tatsächliche Code-Änderungen liefert GitLab schnelleres, fokussierteres Feedback. So bleiben Entwickler im Flow, während gleichzeitig starke Security-Coverage beibehalten wird.
API-Konfigurationen vereinfachen
API-gesteuerte Workflows bieten Power und Flexibilität, können aber auch unnötige Komplexität für Aufgaben schaffen, die Teams regelmäßig durchführen müssen. Das neue Maven Virtual Registry Interface bringt eine UI-Ebene für diese Operationen.
Maven Virtual Registry Interface
Das neue webbasierte Interface für die Verwaltung von Maven Virtual Registries verwandelt komplexe API-Konfigurationen in visuelle Einfachheit und bietet eine intuitivere Experience für Paket-Administratoren und Plattform-Engineers.
Zuvor konfigurierten und warteten Teams Virtual Registries ausschließlich über API-Aufrufe. Dies machte routinemäßige Wartung zeitaufwändig und erforderte spezialisiertes Plattform-Wissen. Das neue Interface beseitigt diese Barriere und macht alltägliche Aufgaben schneller und einfacher.
Mit diesem Update lassen sich nun:
- Virtual Registries erstellen, um die Konfiguration von Abhängigkeiten zu vereinfachen
- Upstreams erstellen und ordnen, um Performance und Compliance zu verbessern
- Veraltete Cache-Einträge direkt im UI durchsuchen und löschen
Diese visuelle Experience hilft, operativen Overhead zu reduzieren, und bietet Entwicklungsteams klareren Einblick, wie Abhängigkeiten aufgelöst werden, sodass bessere Entscheidungen über Build-Performance und Sicherheitsrichtlinien getroffen werden können.
Demo ansehen:
<!-- blank line -->
<figure class="video_container">
<iframe src="https://www.youtube.com/embed/CiOZJPhAvaI?si=cYaoR_OIgqFKbyM2" frameborder="0" allowfullscreen="true"> </iframe>
</figure>
<!-- blank line -->
<p></p>
Enterprise-Kunden sind eingeladen, am Maven Virtual Registry Beta-Programm teilzunehmen und Feedback zu teilen, um das finale Release mitzugestalten.
KI, die sich an den Workflow anpasst
Dieses Release steht für mehr als neue Funktionen – es geht um Wahlmöglichkeiten und Kontrolle. Walkthrough-Video hier ansehen:
<p></p>
<div style="padding:56.25% 0 0 0;position:relative;"><iframe src="https://player.vimeo.com/video/1128992281?badge=0&autopause=0&player_id=0&app_id=58479" frameborder="0" allow="autoplay; fullscreen; picture-in-picture; clipboard-write; encrypted-media; web-share" referrerpolicy="strict-origin-when-cross-origin" style="position:absolute;top:0;left:0;width:100%;height:100%;" title="18.5-tech-demo"></iframe></div><script src="https://player.vimeo.com/api/player.js"></script>
<p></p>
GitLab Premium- und Ultimate-Nutzer können diese Funktionen ab sofort auf GitLab.com und in Self-managed-Umgebungen verwenden. Die Verfügbarkeit für GitLab Dedicated ist für nächsten Monat geplant.
Die GitLab Duo Agent Platform befindet sich aktuell in der Beta – Beta- und experimentelle Features aktivieren, um zu erleben, wie KI mit vollem Kontext die Art und Weise transformieren kann, wie Teams Software entwickeln. Neu bei GitLab? Kostenlose Testversion starten und entdecken, warum die Zukunft der Entwicklung KI-gestützt, sicher und über die umfassendste DevSecOps-Plattform der Welt orchestriert ist.
Hinweis: Platform-Funktionen in der Beta sind im Rahmen des GitLab-Beta-Programms verfügbar. Sie sind während der Beta-Phase kostenlos nutzbar. Bei allgemeiner Verfügbarkeit werden sie als kostenpflichtige Add-on-Option für die GitLab Duo Agent Platform angeboten.
Mit GitLab auf dem aktuellen Stand bleiben
Um sicherzustellen, dass die neuesten Features, Sicherheitsupdates und Performance-Verbesserungen genutzt werden können, empfiehlt sich, die GitLab-Instanz aktuell zu halten. Die folgenden Ressourcen helfen bei der Planung und Durchführung des Upgrades:
- Upgrade Path Tool – aktuelle Version eingeben und die exakten Upgrade-Schritte für die Instanz anzeigen lassen
- Upgrade-Dokumentation – detaillierte Anleitungen für jede unterstützte Version, einschließlich Anforderungen, Schritt-für-Schritt-Anweisungen und Best Practices
Durch regelmäßige Upgrades profitiert das Team von den neuesten GitLab-Funktionen und bleibt sicher und supportet.
Für Organisationen, die einen Hands-off-Ansatz bevorzugen, bietet sich GitLabs Managed-Maintenance-Service an. Mit Managed Maintenance kann sich das Team auf Innovation konzentrieren, während GitLab-Experten die selbstverwaltete Instanz zuverlässig upgraden, sichern und für DevSecOps bereit halten. Für weitere Informationen den Account Manager kontaktieren.
Dieser Blog-Post enthält „forward‑looking statements" im Sinne von Section 27A des Securities Act von 1933 in der jeweils geltenden Fassung und Section 21E des Securities Exchange Act von 1934. Obwohl wir glauben, dass die in diesen Aussagen zum Ausdruck gebrachten Erwartungen angemessen sind, unterliegen sie bekannten und unbekannten Risiken, Unsicherheiten, Annahmen und anderen Faktoren, die dazu führen können, dass tatsächliche Ergebnisse oder Entwicklungen wesentlich abweichen. Weitere Informationen zu diesen Risiken und anderen Faktoren finden sich unter der Überschrift „Risk Factors" in unseren Einreichungen bei der SEC. Wir übernehmen keine Verpflichtung, diese Aussagen nach dem Datum dieses Blog-Posts zu aktualisieren oder zu überarbeiten, es sei denn, dies ist gesetzlich vorgeschrieben.
]]>



 <p></p>
<p></p>